Emerging Architectures for Modern Data Infrastructure
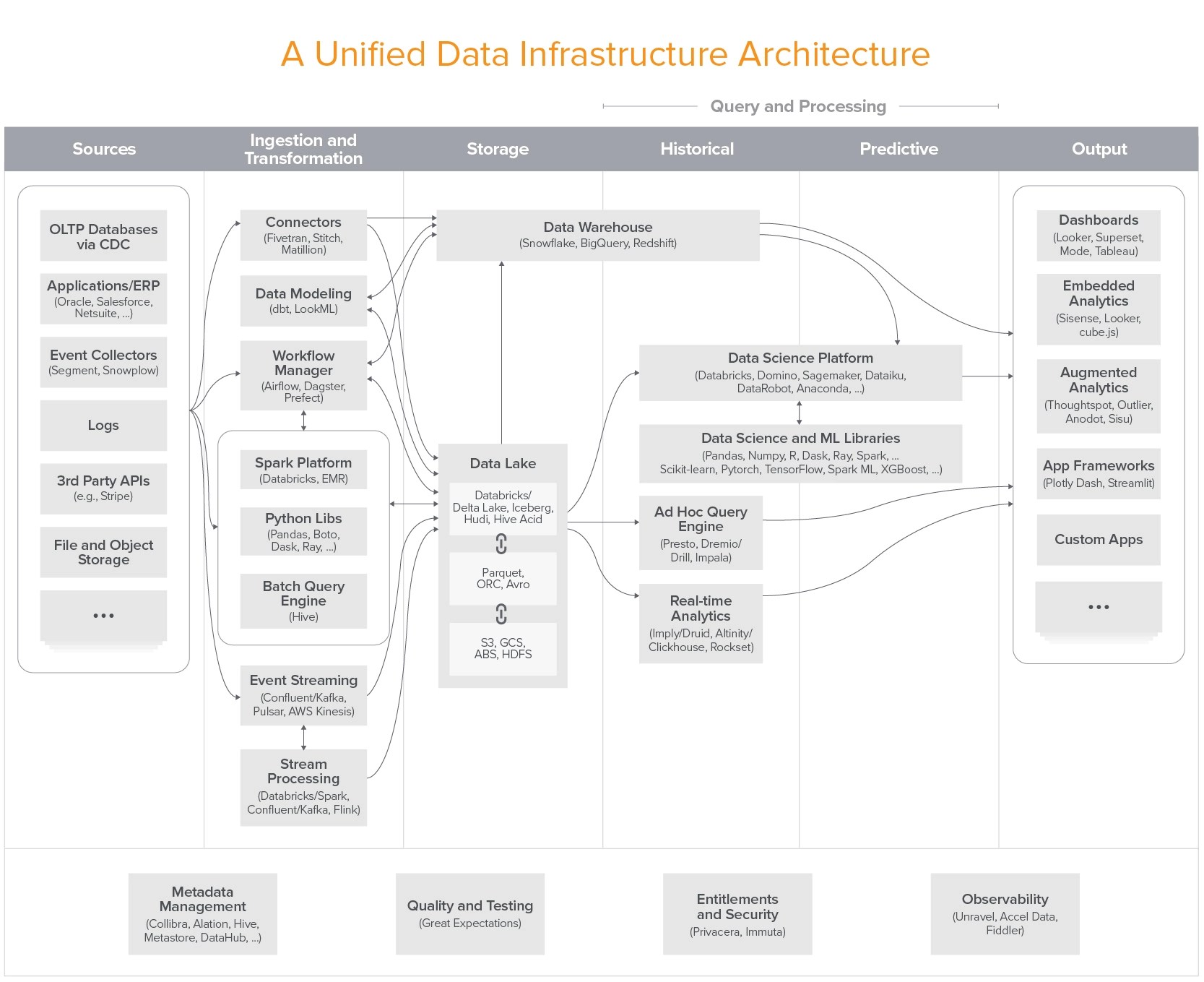 *Source: Andreessen Horowitz
*Source: Andreessen Horowitz
written by Matt Bornstein, Martin Casado, and Jennifer Li
As an industry, we’ve gotten exceptionally good at building large, complex software systems. We’re now starting to see the rise of massive, complex systems built around data – where the primary business value of the system comes from the analysis of data, rather than the software directly. We’re seeing quick-moving impacts of this trend across the industry, including the emergence of new roles, shifts in customer spending, and the emergence of new startups providing infrastructure and tooling around data.
In fact, many of today’s fastest growing infrastructure startups build products to manage data. These systems enable data-driven decision making (analytic systems) and drive data-powered products, including with machine learning (operational systems). They range from the pipes that carry data, to storage solutions that house data, to SQL engines that analyze data, to dashboards that make data easy to understand – from data science and machine learning libraries, to automated data pipelines, to data catalogs, and beyond.
And yet, despite all of this energy and momentum, we’ve found that there is still a tremendous amount of confusion around what technologies are on the leading end of this trend and how they are used in practice. In the last two years, we talked to hundreds of founders, corporate data leaders, and other experts – including interviewing 20+ practitioners on their current data stacks – in an attempt to codify emerging best practices and draw up a common vocabulary around data infrastructure. This post will begin to share the results of that work and showcase technologists pushing the industry forward.
About Me
I'm a data leader working to advance data-driven cultures by wrangling disparate data sources and empowering end users to uncover key insights that tell a bigger story. LEARN MORE >>
comments powered by Disqus