ELT Data Pipelining in Snowflake Data Warehouse

written by Christopher Tao
In my previous post:
Building Snowpipe on Azure Blob Storage Using Azure Portal Web UI for Snowflake Data Warehouse
Snowpipe was introduced to be utilized for automatically discovering new data files in cloud storage (e.g. Azure Blob Storage) and then load the data into a certain table.
Snowpipe is a very convenient tool for the above purposes. However, Snowpipe itself is only considered as the “E” (Extract) of ELT, because only COPY INTO command is allowed in a Snowpipe creating statement. In other words, we can easily achieve the following with it:
- Loading data files in different formats such as CSV, JSON, XML, Parquet and ORC
- Adopting and tweaking the data source for better compatibility such as stripping outer array for JSON and stripping outer element for XML
- Changing column names
- Changing column orders
- Omitting columns
- Parsing data/time string into data/time object
Therefore, for the following reasons, Streams and Tasks are needed for the rest of the data pipelining:
Some data transformation might be necessary, such as numbers calculation and strings concatenation.
The data source is not in typical third-norm format, so it needs to be loaded into multiple tables based on certain relations.
The ELT jobs may not be limited to appending tables, but also include more complex requirements such as SCD (Slowly Changing Dimension) to be implemented.
Therefore, we have to involve other objects in Snowflake to complete the data pipeline.
Snowflake Streams
A Snowflake Stream object is to tracking any changes to a table including inserts, updates and deletes, and then can be consumed by other DML statement. One of the typical usage of steam object is the CDC (Change Data Capture)
Standard v.s. Append-only Stream
There are 2 types of streams that we can define in Snowflake, which are standard and append-only. Standard streams will capture any types of changes to the table, whereas append-only streams only capture inserted rows. The former can be used for general purpose, and the latter can be utilized in a typical ELT model when we only interest in the new rows ingested.
For example, we can have a Snowpipe to automatically ingest the data from CSV files in a cloud storage and copy into a staging table. Then, a stream will capture this bulk-inserting action and record the offset of these new rows.
Stream Offset
Snowflake Streams do not physically store, contain or copy any data. It just takes an snapshot of the tracking table at the current time (e.g. upon stream creation), then every changes made to this table will be recorded by the stream as additional metadata. The difference between the previous version of the table and current version is called the offset.
When other DML statements utilise the offset of the stream, the offset will be reset, and the stream will consider the consumed data as “previous” version of the table. A typical DML statement that consumes stream offset is INSERT INTO ... SELECT ... FROM STREAM.
Here is an example of the stream consumption flow:
Suppose there are already 1 million rows in a table. We create a stream on this table, the stream will have no offset because the current version of the table is snap-shotted.
Suppose there are 1 thousand rows inserted into the table from Snowpipe
COPY INTOstatement.The stream will have these 1 thousand rows recorded as its offset.
Suppose now we read these 1 thousand rows from the stream and insert them into another table.
The stream now will have no offset so that it will be empty, because we have consumed the previous offset.
It is obvious that Snowflake Streams are designed for the ELT processes. For example, we have a high frequency data that is being ingested into the database, and we are consuming the data every 5 minutes. The stream will guarantee that every time we consume the new data has no missing and no overlaps. This indeed can be a logic that is complicated to be implemented in other database management systems, or we may need to use extra programming language achieve this.
Stream Columns
Because stream is actually a snapshot of the original table, all the columns in the original table is also accessible in the stream. For example, if the original table has 3 columns names col1, col2 and col3, then we can simple run
SELECT col1, col2, col3
FROM the_stream;
to retrieve the offset in this stream.
Additionally, there are 3 extra columns that are metadata particularly for stream objects:
METADATA$ACTIONindicates the type of the changes for this row. It can be eitherINSERTorDELETE. Please note that there is no “UPDATE” action. An update of a row will be indicated by 2 rows, one isDELETEof the previous row, the other one isINSERTof the new row. You’ll find this is very convenient because you can get information in the stream regarding what are the specific fields were updated by comparing these two rows.METADATA$ISUPDATEindicates whether this row is generated because of an update. This column is an additional indicator that allows you to get all the rows withINSERTandDELETEbut actually generated because of an update.METADATA$ROW_IDis an unique ID of a particular row. It will not be changed even if the row is updated, and will also remain unchanged for any further updates in the future offsets.
Here is an image from official documentation that presents the data flow very clear.
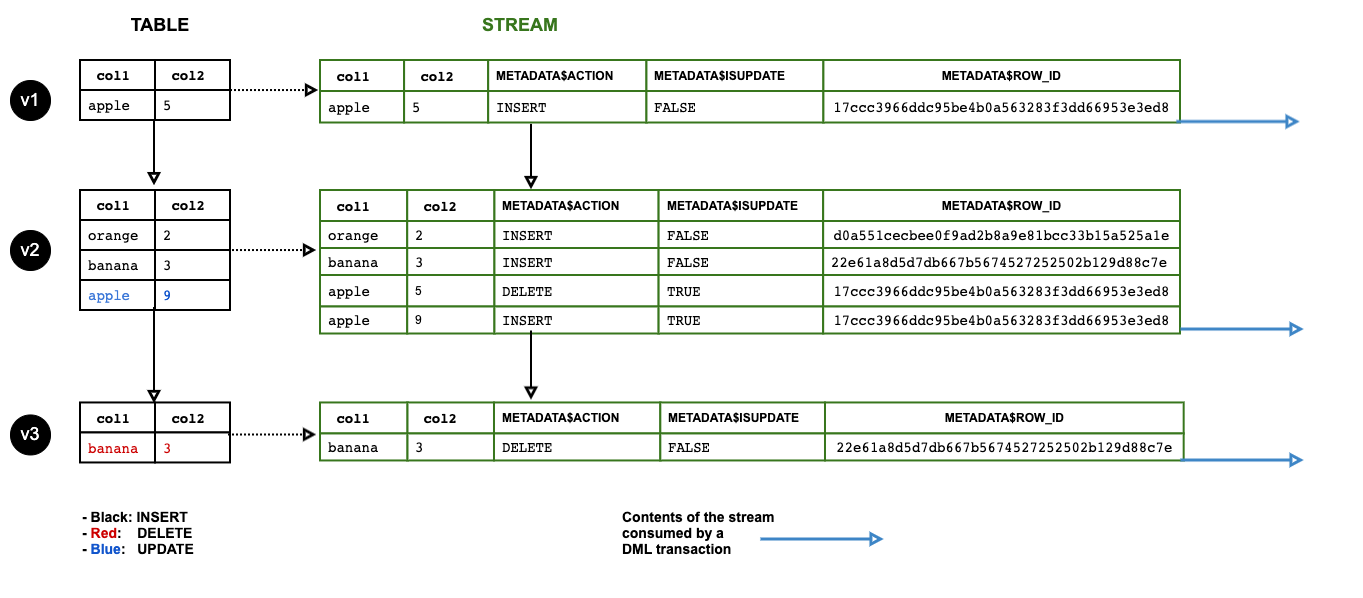
Image courtesy: https://docs.snowflake.net/manuals/user-guide/streams.html
Snowflake Tasks
A Snowflake Task is such an object that can schedule an SQL statement to be automatically executed as a recurring event.
Yes, I use “an” SQL statement for each task. Currently, this is an limitation of Snowflake Tasks. Hopefully in the future updates it will support a transaction will proper BEGIN and COMMIT keywords so that we can execute a series of SQL statements in a transaction, and utilizing a task to schedule this transaction.
Despite the fact that there is such an limitation, Snowflake does provide approaches for multiple SQL statement scheduling, which is called Task Tree. As its name, we can define multiple tasks in a tree structure. Several tips:
A task can have multiple tasks as its offsprings, so the offsprings tasks will be executed when the parent task is finished.
A task can have only one parent task.
Therefore, a task tree is really just a tree, but not DAG. So, you can consider that it can do “fork”, but there is no “join”.
Here is a graph to indicate a simple task tree.
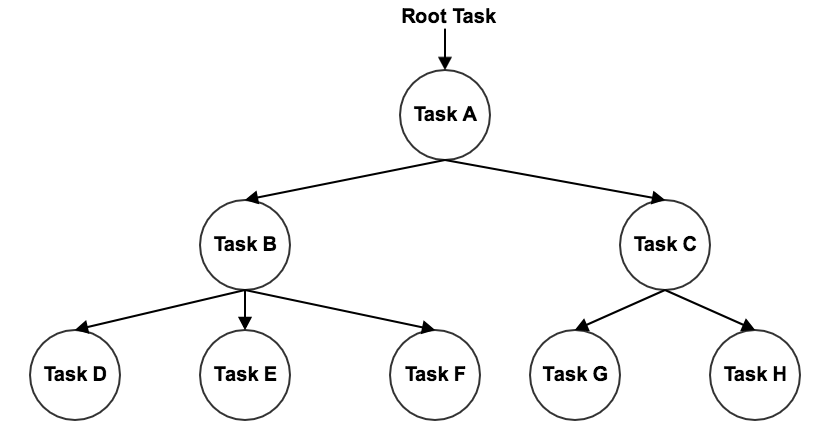
Image courtesy: https://docs.snowflake.net/manuals/user-guide/tasks-intro.html
Trigger a Task
There are two ways for triggering a task, one is by defining a schedule and the other one is triggering by another task.
Snowflake supports two types of task schedule definition, “CRON” expression and time interval. CRON expression can define the exact date/day/time that the task will be triggered, it is very powerful that can achieve any simple to complex requirements, such as:
Run task at certain time of every day
Run task at certain time of a certain day of week
Support timezones
Support daylight saving
For specific syntax of CRON expression, please visit this free website for detailed explanation and experiments:
Free Online Cron Expression Generator and Describer - FreeFormatter.com
Generate a quartz cron expression with an easy to use online interface. Convert a cron expression into a readable text…
www.freeformatter.com
The other approach of scheduling defining is much more straightforward, which is just simple define the time interval. For example, if I want the task to be triggered every 5 minutes, then just define it like this:
SCHEDULE = '5 MINUTE'
Another way of triggering a task is to define a parent task, which is considered to build a task tree. For example, if we want the TASK2 to be triggered when TASK1 is finished, just simple define:
CREATE TASK TASK2
...
AFTER "TASK1"
AS
<SQL>
Conditional Tasks
A task can be defined with a condition by a “WHEN” clause that is used to decide whether this task should be executed.
This is an extremely convenient feature. For example, if you set a condition with your “Root Task”, when the condition is not satisfied, the whole task tree will not run at all.
Also, if this “condition test” is happened in the cloud service layer of Snowflake (using metadata rather than SQL query on a table), it will have ZERO cost for this condition test and consequently having NO cost if the condition is not satisfied.
Using Tasks with Streams
It is very common that the Snowflake Tasks and Streams are utilized together to build a data pipeline. A very typical usage pattern will be:
Snowpipe loads raw data into a staging table.
Snowflake Stream is created on the staging table, so the ingested new rows will be recored as the offsets.
Snowflake Task then consume the Stream offsets by some DML statement to further load the data into production tables, some more complex transformations might included.
In practice, there will be a task tree to execute multiple SQL statements in order to perform the complex transformation, and sometime populate the transformed entries into multiple production tables.
Some intermediate tables might need to be created by the tasks in task tree.
There might be some tasks at the last of the task tree to clean some temporary tables.
We have already introduced the typical scenario that we need to integrate Snowpipe and Stream. Now, for Stream and Task, there is also a very typical usage pattern, that is the system variable SYSTEM$STREAM_HAS_DATA.
Specifically, the variable SYSTEM$STREAM_HAS_DATA will return a boolean value that whether there is an offset in a stream that is consumable. Therefore, we can simple put this condition in the “WHEN” clause of our Task definition. So, the task will not be executed if the there is nothing new in the stream. For example:
CREATE TASK mytask1
WAREHOUSE = mywh
SCHEDULE = '5 minute'
WHEN
SYSTEM$STREAM_HAS_DATA('MYSTREAM')
AS
INSERT INTO ... ;
In this example, only if there is consumable offset in the Stream “MYSTREAM”, the Task “mytask1” will be executed. Otherwise, the task will be skipped and check the condition again after 5 minutes.
One more tip
It is important to remember that a Task that has just been created will be suspended by default. It is necessary to manually enable this task by “altering” the task as follows:
ALTER TASK mytask1 RESUME;
In this article, the Snowflake Stream and Task are introduced theoretically. The general picture of using Snowpipe -> Stream -> Task to build an ELT data pipeline is drawn.
Resources
Official documentation of Snowflake Streams: docs.snowflake.net/manuals/user-guide/streams
Official documentation of Snowflake Tasks: docs.snowflake.net/manuals/user-guide/tasks-intro
Free online CRON expression generator: www.freeformatter.comcron-expression-generator-quartz
*Source: Medium
About Me
I'm a data leader working to advance data-driven cultures by wrangling disparate data sources and empowering end users to uncover key insights that tell a bigger story. LEARN MORE >>
comments powered by Disqus