Data Warehouse Pipelines- Basic Concepts & Roadmap
written by Antony Henao
Five processes to improve your data pipeline operability and performance
Building a data warehouse pipeline can be complex sometimes. If you are starting in this world, you will soon realize there is no right or wrong way to do it. It always depends on your needs.
Yet, there a couple of basic processes you should put in place when building a data pipeline to improve its operability and performance.
In this post, we intend to share you with a roadmap that can help as a guide when building a data warehouse pipeline.
This roadmap is intended to help people to implement the DataOps philosophy when building a data warehouse pipeline through a set of processes.
TL;DR — In the roadmap section we talk about five processes that should be implemented to improve your data pipeline operability and performance — Orchestration, Monitoring, Version Control, CI/CD, and Configuration Management.
Skip right to the roadmap section if you are already familiar with some of the data warehousing terminology — e.g., data lakes, data warehouses, batch, streaming, ETL, ELT, and so on.
Basic concepts
A good place to start in the data warehousing world is the book Cloud Data Management by The Data School.
In this book, they introduce The 4 Stages of Data Sophistication. These stages are a data-pipeline architectural pattern the data industry has been following for years.
Basic Architecture
The basic architecture of a data warehouse pipeline can be split into four parts: data sources, data lake, data warehouse, and data marts.
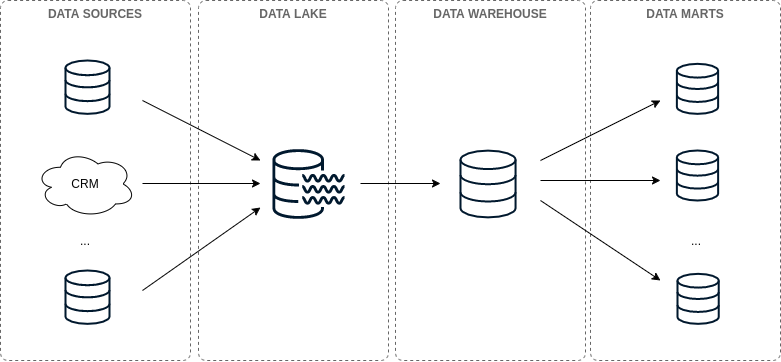
Data Warehouse Pipeline Architecture — Illustration by the Authors based on The 4 Stages of Data Sophistication
According to The Data School, these parts can be defined as follows:
Data sources: The data coming from the business operation. This data comes from production databases, CRMs, APIs, and so on.
Data Lake: “A Data Lake is a storage repository of multiple sources of raw data in a single location.” The data can be found in several formats. Usually, the data can be usually unstructured and a little bit messy at this stage of the data pipeline.
- Data Warehouse: “A Data Warehouse (also commonly called a single source of truth) is a clean, organized, single representation of your data. Sometimes it’s a completely different data source, but increasingly it’s structured virtually, as a schema of views on top of an existing lake.”
<>Data Marts: “A Data Mart is a filtered (and sometimes aggregated) subsection of a Data Warehouse to make it easier for a particular group to query data. It provides a smaller schema with only the relevant tables for the group.”
Together, these four parts represent the basic architecture of a data pipeline. The data is moved from data sources down to the data warehouse. This can be done in performing via batch or stream processing.
Batch vs Streaming
Batch processing is based on loading the data in batches. This means, your data is loaded once per day, hour, and so on.
Stream processing is based on loading the data as it arrives. This is usually done using a Pub/Sub system. So, in this way, you can load your data to the data warehouse nearly in real-time.
These two types of processing are not mutually exclusive. They may coexist in a data pipeline — see Lambda and Kappa architectures for more info. Particularly, we’ll focus on the batch approach in this post.
ETL vs ELT processes
Batch processing implies moving the data from point A to point B. Processes allowing for doing such tasks are known as ETL processes — Extract, Load, and Transform.
These processes are based on extracting data from sources, transforming, and loading it to a data lake or data warehouse.
Although, in recent years, another approach has been introduced: the ELT approach.
The Data School states the difference between these two approaches is:
ETL is the legacy way, where transformations of your data happen on the way to the lake.
ELT is the modern approach, where the transformation step is saved until after the data is in the lake. The transformations really happen when moving from the Data Lake to the Data Warehouse.
ETL was developed when there were no data lakes; the staging area for the data that was being transformed acted as a virtual data lake. Now that storage and compute is relatively cheap, we can have an actual data lake and a virtual data warehouse built on top of it.
ELT approach is preferred over ETL since it fosters best practices making easier data warehousing processes — e.g., highly reproducible processes, simplification of the data pipeline architecture, and so on.
Data Pipeline Roadmap
There are five processes we recommend you should put in place to improve your data pipeline operability and performance.
These processes are Orchestration, Monitoring, Version Control, CI/CD, and Configuration Management.
Such processes are defined based on the DataOps philosophy, which “is a collection of technical practices, workflows, cultural norms, and architectural patterns” enabling to reduce technical debt in the data pipeline — among other things.
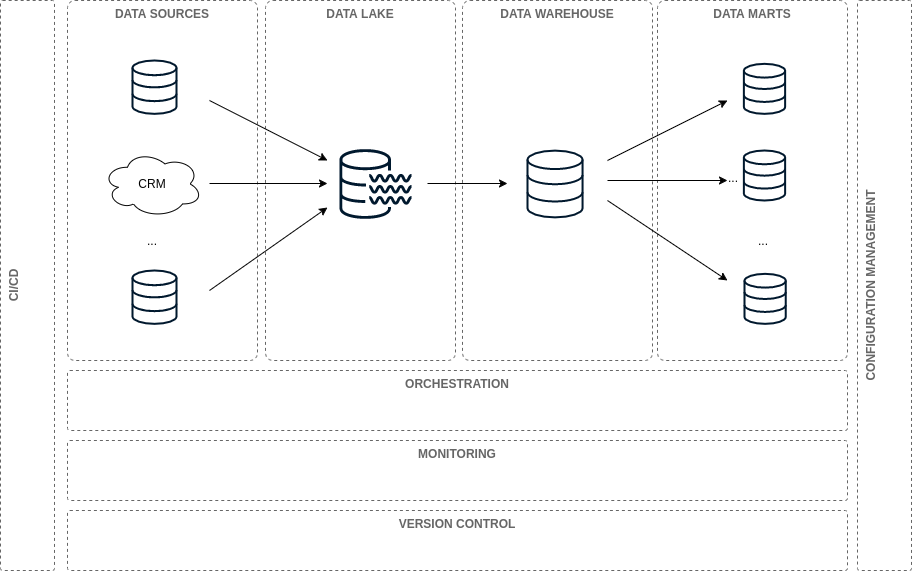
Data Pipeline Roadmap — Illustration by the Authors based on The 4 Stages of Data Sophistication
Orchestration
We all have written CRON jobs for orchestrating data processes at some point in our lives.
When data is in the right place and it arrives at the expected time, everything runs smoothly. But, there is a problem. Things always go wrong at some point. When it happens everything is chaos.
Adopting better practices for handling data orchestration is necessary — e.g., retry policies, data orchestration process generalization, process automation, task dependency management, and so on.
As your pipeline grows, so does the complexity of your processes. CRON jobs fall short for orchestrating a whole data pipeline. This is where Workflow management systems (WMS) step in. They are systems oriented to support robust operations allowing for orchestrating your data pipeline.
Some of the WMS used in the data industry are Apache Airflow, Luigi, and Azkaban.
Monitoring
Have you been in that position where all dashboards are down and business users come looking after for you to fix them? or maybe your DW is down you don’t know? That’s why you should always monitor your data pipeline!
Monitoring should be a proactive process, not just reactive. So, if your dashboard or DW is down, you should know it before business users come looking out for you.
To do so, you should put in place monitoring systems. They run continuously to give you realtime insights about the health of your data pipeline.
Some tools used for monitoring are Grafana, Datadog, and Prometheus.
CI/CD
Does updating changes in your data pipeline involve a lot of manual and error-prone processes to deploy them to production? If so, CI/CD is a solution for you.
CI/CD stands for Continuous Integration and Continous Deployment. The goal of CI is “to establish a consistent and automated way to build, package, and test applications”. On the other hand, CD “picks up where continuous integration ends. CD automates the delivery of applications to selected infrastructure environments.” — more info here.
CI/CD allows you to push changes to your data pipeline in an automated way. Also, it will reduce manual and error-prone work.
Some tools used for CI/CD are Jenkins, GitlabCI, Codeship, and Travis.
Configuration Management
So…Imagine your data pipeline infrastructure breaks down for any reason. For example, you need to deploy again the whole orchestration pipeline infrastructure. How you do it?
That’s where configuration management comes in. Configuration management “deals with the state of any given infrastructure or software system at any given time.” It fosters practices like Infrastructure as Code. Additionally, it deals with the whole configuration of the infrastructure — more info here.
Some tools used for Configuration Management are Ansible, Puppet, and Terraform.
Version control
Finally, one of the most known processes in the software industry: version control. We all have had problems when version control practices are not in place.
Version control manages changes in artifacts. It is an essential process for tracking changes in the code, iterative development, and team collaboration.
Some tools used for Version Control are Github, GitLab, Docker Hub, and DVC.
Conclusions
In this post, we recommended five processes you should put in place to improve your data pipeline operability and performance.
These processes are usually overlooked when implementing a data pipeline. We hope this information allows you to be aware of them.
More importantly, we expect this roadmap allows you to take your data pipeline to another level of operability!
*Source: Medium
About Me
I'm a data leader working to advance data-driven cultures by wrangling disparate data sources and empowering end users to uncover key insights that tell a bigger story. LEARN MORE >>
comments powered by Disqus