Skills for Being a Good Data Engineer
written by Benjamin Rogojan
A data engineer specializes in several specific technical aspects. Data engineers have solid automation/programming skills, ETL design, understand systems, data modeling, SQL, and usually some other more niche skills. For instance, some data engineers start to dabble with R and data analytics. This will also be driven by their specific role. As a data engineer, I have been asked to set up basic websites, develop APIs and create models and algorithms.
Due to the various skill sets and tools, our team has developed a set of resources that can help someone looking to break into the data engineering field. Below we will be talking ETL tools, SQL, System Design, etc.
ETL Tools
Let’s start with the first skill. Designing ETLs. There are many ETL tools out there. SSIS (or Azure Data Factory), Airflow, Informatica, just to name a few. They all tout that they will solve all your problems. But like any tool, they have their pros and cons.
SSIS
For instance, SSIS is really developed for SQL server. Although it allows you to load data into many other databases. It is clearly focused on the Microsoft environment. In addition, SSIS is great for those who are not strong programmers. The tool is GUI based and allows you to drag and drop tasks that just need you to change parameters. These tasks can allow you to send emails automatically, manage dependencies and allows for many other helpful features.
All this said, it also requires an understanding of all these tasks. This makes it harder for data engineers who prefer programming vs. working with a GUI. GUIs require specific knowledge of where properties are hidden and limited to the framework provided. This can be very frustrating if you are more comfortable editing code because what might take you 1 minute to write in code, will require 30 mins to an hour of tinkering in SSIS. Also, for anyone who has ever developed an SSIS pipeline, you are very aware of the fact that one small metadata change can take down the entire DB(of course, this is not an SSIS exclusive problem).
For a good intro to SSIS, check out this video by WiseOwls. This is a great place to learn about all tricky to get to properties and possible features you might want to use. Here is a great video on performing basic tasks.
Informatica provides a lot more features similar to SSIS but is usually much better at handling large data and different types of database systems. Here is a great intro to the tool.
Airflow
Now finally there is Airflow. An airflow is a great tool because it does more than just move data from point a to point b. It also does a lot of the dependency management tracking and has a great UI that makes it easy to manage jobs.
Airflow is written in Python which means your team will need to be coding proficient as well as understand how to manage Airflow. If your team has lots of complicated pipelines, then one of your employees might be stuck just making sure all the ETL tasks are running and troubleshooting anything that breaks in Airflow.
This is not unique only to Airflow. SSIS also requires understanding SQL Server agent for automation but since this is more GUI based it can be easier to manage. Once you have hundreds of pipelines going in Airflow, it can be difficult to track where data is coming from and where it is going.
*Sometimes, you even end up with what we call spaghetti tables. This is like spaghetti code, but with data.
Airflow can be a little less accessible for non-Linux/programmer types. So this really depends on your team’s size as well as the complexity of your team’s pipelines.
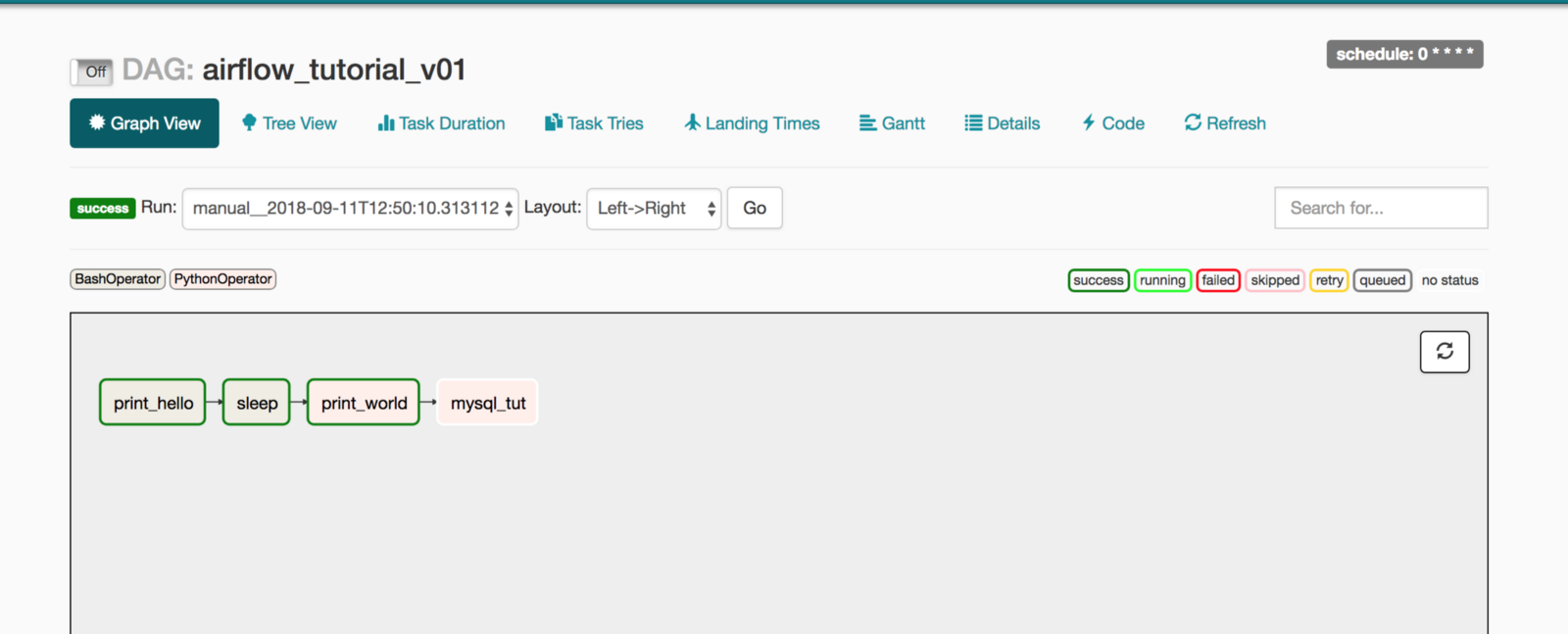
Here is a great start to your Airflow journey. This series covers what Airflow is and takes you through the steps needed for developing your first pipeline
Those were a few examples of ETL tools. There are plenty more, usually split between GUI and purely code-based. But this is a great start.
Data Modeling And Data Warehouses
Let’s next discuss the next key component that we believe gets overlooked. That is data modeling/data warehousing. Some companies split the work of data modeling and ETL engineering. This might make sense at some companies. We just believe it is just as important that a data engineer not only develop ETLs that populate tables, but they also understand how to develop a data warehouse.
Data warehouses and data modeling typically involves pulling data from operational systems using an API or extracting the data in another way in order to allow analysts to analyze historical data. This data is then reshaped in order to be more efficient as well as better represent the actual transactions and changes that occur in a business process.
Now there are a couple caveats. It used to be that there were only a few paradigms for designing data warehouses. Due to new data systems like Hadoop, data warehouses can’t always be designed in the traditional way.
**for those who haven’t used Hadoop, the inability to run certain statements like “UPDATE” limits your abilities drastically.
If you are using a traditional relational database then you will need to learn about a couple key concepts. This includes the star schema, denormalization, analytical tables and slowly changing dimensions (to start). These are some of the key data modeling concepts that usually come into play. Understanding what each of these concepts is, and how they apply to a data engineer is necessary.
Here are some great resources for you to learn more about it.
Star Schema
A star schema is one of the simplest data models you can create as a data engineer. In the center is what we call a fact table. This table represents the actual transactions that occurred. This might be purchases of products or visits to a hospital. Each transaction has a bunch of id columns that map to the dimension tables. Dimension tables contain information that helps describe what entities were involved in the transaction. Where did this event happen, what did the person buy, etc. For a more in-depth look, please check out the video below!
Slowly Changing Dimensions
Transactions are constantly occurring. Dimensions, for the most part, stay the same. But, there are cases where the store manager might change or maybe a person changes job roles. These might be considered slowly changing dimensions. We manage this through several methods described in the video below.
Data Denormalization
Data denormalization is attached to data modeling. We wanted to have a separate video that talked about it just to make sure the concept was clear. In fact, if you are going for an interview, a question might be asked along the lines of why do we normalize vs denormalize.
System Designs
Next, let’s talk about automation and system design. Data engineers are not exactly software engineers. We don’t develop services and apps. We do however need to automate much of our work and often that all fit in a much larger system.
That system often has tons of limitations, dependencies and feature requirements. This means data engineers can’t just design ETLs and automated scripts without thinking how things fit in the bigger picture.
Not only that, how we design our tables and ETL defines how the system can be used in the future. This means we not only need to make sure our whole system meets the current requirements. It also means we need to think about what questions managers might ask in the future, and what features we will need to allow for.
This is why we think it can be helpful just to look at some system design interview questions for software engineers. At the end of the day, the skills transfer over pretty well. These videos will often show how you can take a problem, look at the features and limitations and implement a high-level solution
For instance, this YouTube video does a great job of laying out the requirements and features for the task and then digging into how he would solve each problem.
Another great video relates to architecture design at Uber engineering:
SQL
SQL is most data engineers’ bread and butter. Even modern data systems like Hadoop have Presto and Hive layered on top which allows you to use SQL to interact with Hadoop instead of Java or Scala.
SQL is the language of data and it allows data engineers to easily manipulate, transform and transfer data between systems. Unlike programming, it is almost the same between all databases. There are a few that have decided to make very drastic changes. Overall, SQL is worth learning, even in today’s landscape.
Similar to SSIS, WiseOwl makes great videos that could benefit you. They have a few playlists so check them all out!
SQL Queries
SQL Procedures And Programming
Tableau or other Data Viz tool
Data visualization isn’t part of every data engineer’s regular day-to-day. It is not uncommon that a data engineer will have to develop reports and dashboards. There are lots of off the shelf tools that are very easy to use. Tableau, SSRS, D3.js etc. Except for D3.js, these are all mostly drag and drop tools.
Tableau has a great set of resources
For Fun
Any engineer spends most of their day in meetings and staring at computers. So along with all these great resources for learning. We wanted to provide some of our favorite resources for laughs as engineers. All of these comics, videos, and websites involve technology and are great for poking fun at our profession.
The Tech Lead
The tech lead or Patrick Shyu is a youtube/developer/comedian(of sorts) who produces videos that are somewhere between a combination of practical advice and straight up dry comedy. Honestly, it can be difficult to tell when he is speaking sarcastically vs. when he might actually be speaking a real truth for being an engineer. That is what makes his videos so funny. As an engineer, you will get when he is kidding (which is most of the time) and when he isn’t. But he keeps such a straight face and has no change in pitch that it is hilarious.
He covers a lot of topics, like interview tips, how to develop anti-patterns (yes you read that right), and a plethora of other often hot topics. Here is one of his videos.
Another great comedic relief source is committed strip. Now there are plenty of classic engineering funnies. Just look at Dilbert. However, there is something fresh about commit strip. It really focuses on a lot more of the idiosyncrasies of development. Dilbert can really speak to most anyone in an office. Whereas Commitstrip is very much targeted at developers, system admins, and TPMs. They often will poke fun at nuances of programming languages, the bug cycle or other very specific topics. This just increases the humor for those of us who have actually lived the pain the comics are mocking.

Finally, this is for those of you who are Linux fans. Nixcraft has a blog with lots of tips and tricks for Linux and other systems. However, his Twitter feed will often have a much higher ratio of memes, videos and all around funny media vs. advice for any developer. He usually focuses around Linux, but does spend a decent amount of time also retweeting developer comics and memes

These videos and resources cover some of the basic concepts every data engineer needs to know. From here there are plenty of other skills you can build that will also be useful. For instance, learning R or python for analytical purposes can be a career booster. If you are looking for book recommendations, check these out!
- Kimball’s Data Warehouse Toolkit Classics, 3 Volume Set
- Architecting Modern Data Platforms: A Guide to Enterprise Hadoop at Scale
- Data Warehouse Design: Modern Principles and Methodologies
*Source: Coriers
About Me
I'm a data leader working to advance data-driven cultures by wrangling disparate data sources and empowering end users to uncover key insights that tell a bigger story. LEARN MORE >>
comments powered by Disqus