Future of Data Warehousing

written by Simon Späti (with some grammatical edits by me)
Today, there are 6,500 people on LinkedIn who call themselves data engineers according to stitchdata.com. In San Francisco alone, there are 6,600 job listings for this same title. The number of data engineers has doubled in the past year, but engineering leaders still find themselves faced with a significant shortage of data engineering talent. So is it really the future of data warehousing? What is data engineering? These questions and much more I want to answer in this blog post.
In unicorn companies like Facebook, Google, Apple where data is the fuel for the company, mostly in America, is where data engineers are mostly used. In Europe, the job title does not completely exist besides the startup mecca Berlin, Munich, etc. They are called or included in jobs like software engineer, big data engineer, business analyst, data analyst, data scientist and also the business intelligence engineer. Myself, I started as a business intelligence engineer and using more and more time on the engineering rather the business part, that’s why I am starting this blog from the data warehousing angle.
What is a Data Warehouse?
What is data warehousing or what is a business intelligence engineer doing, and why are they using a data warehouse?
To use the analogy to a physical retail-type warehouse, you want to sell very structured products in the most efficient way to your customers. In a data warehouse (DWH) you have typically structured data and optimised them for business users to query. If you dig a little deeper, you offload data from the trucks in the back of the physical shop, before it gets sorted and structured into the warehouse for the customers to buy. In a DWH you basically do the same, just with data. As you see in the DWH architecture below, the offloading area in the back of the store is your stage area where you store the source data from your operational systems or external data.
A traditional Data Warehouse architecture by Wikipedia:
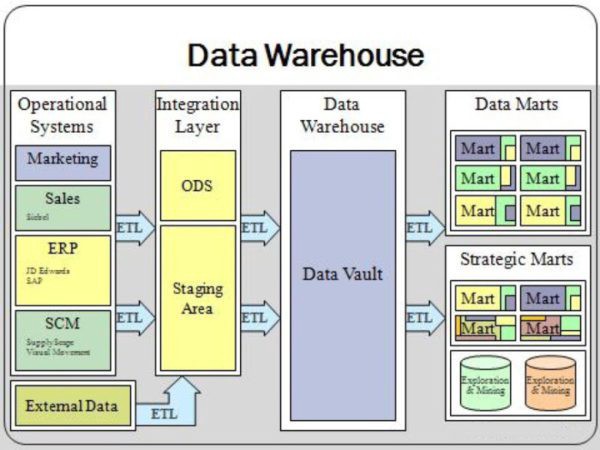
The physical warehouse where the customers buying the articles is in a DWH normally the so-called data mart. The data processed between each layer seen in the architecture above is called ETL (Extract Transform Load). This is not to confuse with ELT (Extract Load Transform) which is the common mythology data lakes (more in my recent post). In a DWH you always transform to get data as clean and structured as possible.
Why have a Data Warehouse?
Besides the obvious reasons of a shop explained above, a data warehouse gives you big advantages:
- In theory: Integration and transformation of raw data of an organization from multiple sources (mostly very structured like SAP, CRM, Excel, etc.) into meaningful and useful information, historical stored.
- In practice: Similar a cockpit in an aeroplane — All Measures and KPI’s are at one place in order to steer the plane and take the right decisions
- It allows businesses to make better decisions by accessing the data well structured
- It helps to make informed decisions based on facts
- It improves the efficiency of business operations
- It enhances the quality of customer service
- The visual products from business intelligence based on top of a data warehouses are largely:
- Ad hoc Reporting
- Standard Reporting
- Dashboards / Cockpits
What is Data Engineering?
Data engineering is the less famous sibling of data science. Data science is growing like no tomorrow and so does data engineer, but much less heard. Compared to existing roles it would be a software engineering plus business intelligence engineer including big data abilities as the Hadoop ecosystem, streaming and computation at scale. Business creates more reporting artifacts themselves but with more data that needs to be collected, cleaned and updated near real-time and complexity is expanding every day. With that said more programmatic skills are needed similar to software engineering. The emerging language at the moment is Python (more on that below) while used in engineering with tools alike Apache Airflow as well as data science with powerful libraries. Where today as a BI-engineer you use SQL for almost everything except when using external data from an FTP-server for example. You would use bash and PowerShell in the nightly batch jobs. But this is no longer sufficient and because it gets a full-time job to develop and maintain all these requirement and rules (called pipelines), the data engineering is needed.
The role of a data engineer
In order to get high quality and frequently updated data sets, it is important to distinguish between data pipelines that are done and cleaned by data engineers and all the others that are mostly exploratory. We at Airbus use a folder that is called “cleaned” and all data sets produced there are constantly updated, documented and of the highest quality. Based on these data sets you create your own. We use the data lake solution Palantir Foundry (brand name of Airbus: Skywise) which provides you with a map where you see the data lineage easily. Documentation and metadata to each data set are crucial as otherwise, you lose the overview of your data, which is also one main task of a data engineer.
Services that a data engineer provides
Another important task or service which a data engineer provides is automation that data scientists or data analysts do manually. A good overview what task this includes are provided by Maxime Beauchemin, the founder of Apache Airflow, a tool that helps a data engineer to lift the majority of tasked mentioned:
- data ingestion: services and tooling around “scraping” databases, loading logs, fetching data from external stores or APIs, …
- metric computation: frameworks to compute and summarise engagement, growth or segmentation related metrics
- anomaly detection: automating data consumption to alert people anomalous events occur or when trends are changing significantly
- metadata management: tooling around allowing generation and consumption of metadata, making it easy to find information in and around the data warehouse
- experimentation: A/B testing and experimentation frameworks is often a critical piece of company’s analytics with a significant data engineering component to it
- instrumentation: analytics starts with logging events and attributes related to those events, data engineers have vested interests in making sure that high-quality data is captured upstream
- dependencies: pipelines that are specialized in understand series of actions in time, allowing analysts to understand user behaviours”
While the nature of the workflows that can be automated differs depending on the environment, the need to automate them is common across the board.
- Maxime Beauchemin
When is a data engineer needed?
I believe, that not every company is in need of data engineers. These skills are mostly required if the company either:
- has already a product that is fully web-based and therefore data-driven or
- the need or desire to analyse lots of data (Volume) from any kind of sources (Variety) and fast (Velocity) to get the insights (Value and Veracity) (see more about the five V’s of Big Data)
Data engineer job description and skills
If English is the language of business, SQL is the language of data and Python the language of engineering. While technology disappears often, SQL is still here. This means you need a reliable understanding of:
- SQL to a high level of complexity
- Data modelling techniques: ERDs and dimensional modelling
- Solid ETL understanding
- Architectural projections: needs to have a high-level understanding of most of the tools, platforms, libraries and other resources at its disposal
- Ability to connect the dots from source to destination with any programming language that does the job best. (Probably Python at the moment)
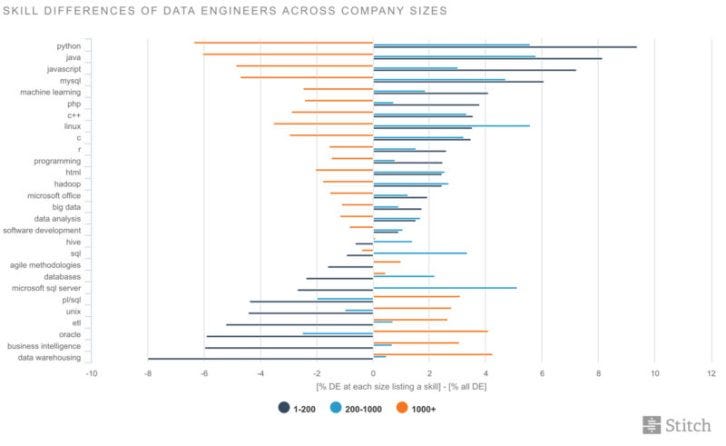
Stitchdata.com anticipated that as company size increased, so would the focus on scaling-related skill. However, that’s not the story the data told. Instead, data engineers at larger companies tend to be more focused on “enterprise” skills like ETL, BI, and data warehousing, whereas data engineers at smaller companies focus more on core technologies:
The tool language, Python
The growth of major programming languages
Programming languages have always come and gone, but in the last couple of years, Python rises on top of the popularity. The question is why. One valid reason for sure is because of the rise of the data engineers but also the use of libraries for data science and data analytics.
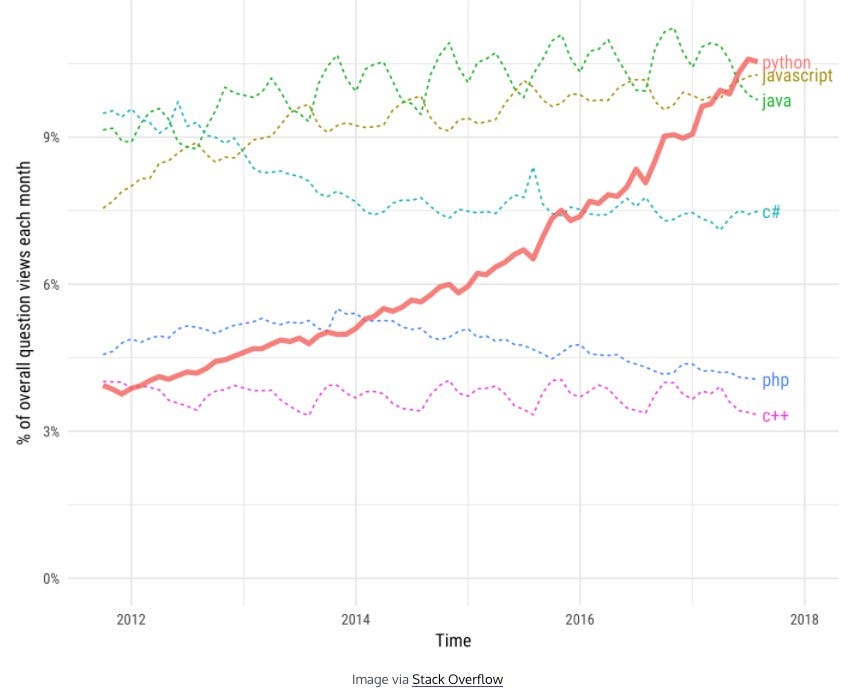
According to the Codeacademy and their source data from Stack Overflow, they say it’s connected to the rise of data science. This and machine learning were the biggest trends in tech 2017. Additionally, Python has become a go-to language for data analysis. With data-focused libraries like pandas, NumPy, and matplotlib, anyone familiar with Python’s syntax and rules can deploy it as a powerful tool to process, manipulate, and visualise data.
Related to the rise of data science and data engineering, it’s clear to me that Python is here to stay and it’s becoming the Swiss Army Knife of programming languages.
Python for data engineers
But for what can you use Python in data engineering. For example, you use it for data wrangling (reshaping, aggregating, joining disparate sources, etc.) which mostly done with the library Pandas, small-scale ETL, API interaction (our presentation usually happens in Tableau which has Python APIs) and automation with Apache Airflow, which is also natively in Python.
“Apache Airflow has several building blocks that allow Data Engineers to easily piece together pipelines to and from different sources. Because it is written in Python, Data Engineers find it easy to create ETL pipelines by just extending classes of Airflow’s DAG and Operator objects. And this allows us to write our own Python code to create any ETL we wish, with the structure given by Airflow. Airflow uses several packages mentioned all ready to do the job:
botofor S3 handling, pandas for obvious advantages with data frames,psycopg2for popular integrations with Postgres and Redshift, and several more.”
Business Intelligence Engineer vs Data Engineer
As already mentioned in further up, the data engineer has the skillset of a business intelligence engineer plus also solid programming and big data skills. I believe BI-engineers will transit over to a data engineer anyway, depending on the size of a company. But why? What is changing/has changed?
What has changed
As the power of computers and especially the speed of the internet is growing, more data can be collected and needs to be analysed. Therefore many parameters around the data warehouse environment have or will change. Below the points that I see with most influence:
- Computers have gotten faster and reports can be built directly on source data, with no persistent layer needed for performance optimization - a semantic layer is enough
- Business has no time to wait for ETL to be finished during the night, data needs to refresh immediately (near real-time)
- Keeping up with customer demand through new BI deployments
- Older BI deployments cannot keep pace with success
- “The main factors that drive development and deployment of new data warehouses are being agile, leveraging the cloud and the next generation of data (as it relates to real-time data, streaming data and data from IoT devices).” -Brian E. Thomas
- (Data warehouse automation can help here, read more in my recent posts)
- Structure needs to put in place after you collect data (ELT instead of ETL).
- Easy collaboration and exchange of data is needed
- Governance getting more important as more data is stored in order to have the full overview of the data, timeframe and quality
- New trends, tools, technologies and competitors are arising all the time, companies must be on top of that
ETL is changing
Furthermore the way we do ETL is changing as well, as Maxime Beauchemin, data engineer at Airbnb writes:
Product know-how on platforms like Informatica, IBM Datastage, Cognos, AbInitio or Microsoft SSIS isn’t common amongst modern data engineers, and being replaced by more generic software engineering skills along with understanding of programmatic or configuration driven platforms like Airflow, Oozie, Azkabhan or Luigi. It’s also fairly common for engineers to develop and manage their own job orchestrator/scheduler.”
He is also saying that code is the best abstraction there is for software rather than using drag and drop tools (ETL-tools). Most important what I see as well, that the transformation logic is of a higher need and shouldn’t be locked away exclusively for BI developers.
Data Modeling is changing
As you can’t change ETL without modelling differently, also this is changing:
- Further denormalization for performance gains is mostly compensated with faster databases engines or cloud solutions.
- Maintaining surrogate keys in dimensions can be tricky and not human-friendly as we prefer business keys. With the popularity of document storage and cheap blobs in cloud storage, it is becoming easier to create and develop database schemas dynamically without writing DML-statements.
- Systematically snapshoting dimension compared to handle complex and maybe counter-intuitive slowly changing dimension (SCD) is a way to simplify track changes in a DWH. Is it also easy and relatively cheap to denormalise dimension’s attribute directly on the fact table to keep important information at the moment of the transaction.
- Conformed dimensions and conformance as in general is extremely important in nowadays data warehouse and data environments. But to be more collaborative and work on same objects it is a necessary trade-off to loosen it up.
- Other business departments are becoming more data-savvy than ever before. In that sense data needs to become more real-time rather than batch processing and precomputed calculations, this can be done more ad-hoc with new fast technologies like Spark that run complex jobs ad-hoc and on-demand.
Education is changing
Facebook, Airbnb and other companies taking it a step into so-called “Data Camps or Data University” to educate internal employees in respect of data to get more data savvy.
Conclusion
So after all, is the data engineer the new business intelligence engineer? I would say in the long run yes. I imagine that data warehouses — in any way — will always be a need for the business, where the data is fully structured and easily accessible. But how we build DWHs (or something similar) will change and therefore more engineering and data engineer resources will be needed.
Originally published at sspaeti.com on March 8, 2018.
*Source: Hacker Noon
About Me
I'm a data leader working to advance data-driven cultures by wrangling disparate data sources and empowering end users to uncover key insights that tell a bigger story. LEARN MORE >>
comments powered by Disqus