Data Engineers vs. Data Scientists
The two positions are not interchangeable—and misperceptions of their roles can hurt teams and compromise productivity.
written by Jesse Anderson
It’s important to understand the differences between a data engineer and a data scientist. Misunderstanding or not knowing these differences are making teams fail or underperform with big data.
A key misunderstanding is the strengths and weaknesses of each position. I think some of these misconceptions come from the diagrams that are used to describe data scientists and data engineers.
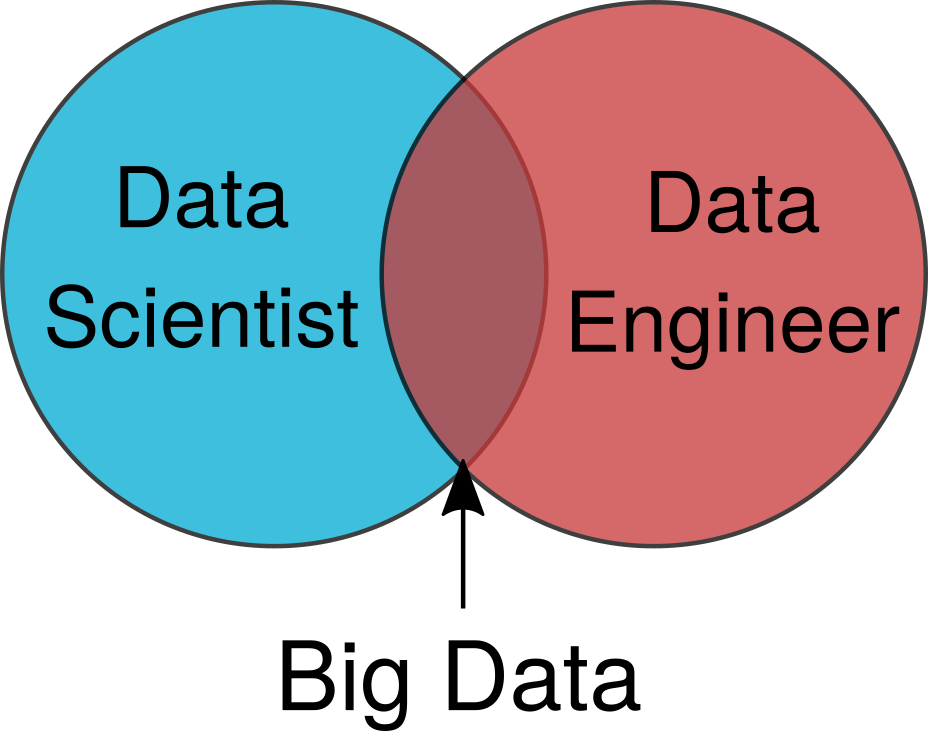
Figure 1. Overly simplistic venn diagram with data scientists and data engineers. Illustration by Jesse Anderson.</sub
Venn diagrams like Figure 1 oversimplify the complex positions and how they’re different. It makes the two positions seem interchangeable. Yes, both positions work on big data. However, what each position does to create value or data pipelines with big data is very different. This difference comes from the base skills of each position.
What are data scientists and data engineers?
When I work with organizations on their team structures, I don’t use a Venn diagram to illustrate the relationship between a data engineer and a data scientist. I draw the diagram as shown in Figure 2.

Figure 2. Diagram showing the core competencies of data scientists and data engineers and their overlapping skills. Illustration by Jesse Anderson and the Big Data Institute.
Data scientists’ skills
At their core, data scientists have a math and statistics background (sometimes physics). Out of this math background, they’re creating advanced analytics. On the extreme end of this applied math, they’re creating machine learning models and artificial intelligence.
Just like their software engineering counterparts, data scientists will have to interact with the business side. This includes understanding the domain enough to make insights. Data scientists are often tasked with analyzing data to help the business, and this requires a level of business acumen. Finally, their results need to be given to the business in an understandable fashion. This requires the ability verbally and visually communicate complex results and observations in a way that the business can understand and act on them.
My one sentence definition of a data scientist is: a data scientist is someone who has augmented their math and statistics background with programming to analyze data and create applied mathematical models.
A common data scientist trait is that they’ve picked up programming out of necessity to accomplish what they couldn’t do otherwise. When I talk to data scientists, this is a common thing they tell me. In order to accomplish a more complicated analysis or because of an otherwise insurmountable problem, they learned how to program. Their programming and system creation skills aren’t the levels that you’d see from a programmer or data engineer—nor should they be.
Data engineers’ skills
At their core, data engineers have a programming background. This background is generally in Java, Scala, or Python. They have an emphasis or specialization in distributed systems and big data. A data engineer has advanced programming and system creation skills.
My one sentence definition of a data engineer is: a data engineer is someone who has specialized their skills in creating software solutions around big data.
Using these engineering skills, they create data pipelines. Creating a data pipeline may sound easy or trivial, but at big data scale, this means bringing together 10-30 different big data technologies. More importantly, a data engineer is the one who understands and chooses the right tools for the job. A data engineer is the one who understands the various technologies and frameworks in-depth, and how to combine them to create solutions to enable a company’s business processes with data pipelines.
In my experience, a data engineer is only tangentially involved in the operations of the cluster (in contrast to what’s said about data engineers here). Though some data science technologies really require a DevOps or DataOps set up, the majority of technologies don’t. Just like with most programers, I wouldn’t allow them direct access to the production system. That’s primarily the job for system administrators or DevOps.
Overlapping skills
There is an overlap between a data scientist and a data engineer. However, the overlap happens at the ragged edges of each one’s abilities.
For example, they overlap on analysis. However, a data scientist’s analytics skills will be far more advanced than a data engineer’s analytics skills. A data engineer can do some basic to intermediate level analytics, but will be hard pressed to do the advanced analytics that a data scientist does.
Both a data scientist and a data engineer overlap on programming. However, a data engineer’s programming skills are well beyond a data scientist’s programming skills. Having a data scientist create a data pipeline is at the far edge of their skills, but is the bread and butter of a data engineer. In this way, the two roles are complementary, with data engineers supporting the work of data scientists.
You’ll notice that there is another overlap between a data scientist and a data engineer—that of big data. Understanding each positions’ skills better, you can now understand the overlap. Data engineers use their programming and systems creation skills to create big data pipelines. Data scientists use their more limited programming skills and apply their advanced math skills to create advanced data products using those existing data pipelines. This difference between creating and using lies at the core of a team’s failure or underperforming with big data. A team that expects their data scientists to create the data pipelines will be woefully disappointed.
When organizations get it wrong
It’s unfortunately common for organizations to misunderstand the core skills and roles of each position. Some organizations believe that a data scientist can create data pipelines. A data scientist can create a data pipeline after a fashion. The issues with a data scientist creating a data pipeline are several fold. Remember that a data scientist has only learned programming and big data out of necessity. They’re smart people and can figure things out—eventually. Creating a data pipeline isn’t remotely their core competency.
From the managerial point of view, the data science team will appear stuck. You’ll look around or hear about other teams and compare their progress to your team’s progress. It will appear as if the data science team isn’t performing or greatly under performing. This is an unfair evaluation based on misunderstanding the core competency of a data scientist.
Data scientists doing data engineering
I’ve seen companies task their data scientists with things you’d have a data engineer do. The data scientists were running at 20-30% efficiency. The data scientist doesn’t know things that a data engineer knows off the top of their head. Creating a data pipeline isn’t an easy task—it takes advanced programming skills, big data framework understanding, and systems creation. These aren’t skills that an average data scientist has. A data scientist can acquire these skills; however, the return on investment (ROI) on this time spent will rarely pay off. Don’t misunderstand me: a data scientist does need programming and big data skills, just not at the levels that a data engineer needs them.
There is also the issue of data scientists being relative amateurs in this data pipeline creation. A data scientist will make mistakes and wrong choices that a data engineer would (should) not. A data scientist often doesn’t know or understand the right tool for a job. Everything will get collapsed to using a single tool (usually the wrong one) for every task. The reality is that many different tools are needed for different jobs. A qualified data engineer will know these, and data scientists will often not know them.
A recent example of this was a data scientist using Apache Spark to process a data set in the 10s of GB. Yes, Spark can process that amount of data. However, a small data program would have been much, much faster and better. Their Spark job was taking 10-15 minutes to execute, but the small data RDBMS took 0.01 seconds to accomplish the same thing. In this case, the data scientist solved the problem after a fashion, but didn’t understand what the right tool for the job was. Times that 15 minutes spent running that job by 16 times in a day (that’s on the low end for analysis), and your data scientist is spending four hours a day waiting because they’re using the wrong tool for the job.
At another organization, their data scientists didn’t have any data engineering resources. The data scientists would work on the problems until they got stuck on a data engineering problem they couldn’t solve. They’d report back to the business that they couldn’t finish things and there it sat, half-finished. This led to the data scientists wasting their time up to that point, and left, by their estimate, millions of dollars on the table because things couldn’t be finished.
A more worrisome manifestation of having a data scientist do a data engineer’s work is that the data scientist will get frustrated and quit. I’ve talked to many data scientists at various organizations who were doing data engineer work. The conversation is always the same—the data scientist complains that they came to the company to data science work, not data engineering work. They’ll do data engineering work in a pinch to get something done, but having a data scientist do data engineer work will drive them crazy. They will quit and you will have 3-6 months to get your data engineering act together. I talk more about these issues in another post.
Ratios of data engineers to data scientists
A common issue is to figure out the ratio of data engineers to data scientists. The general things to consider when choosing a ratio is how complex the data pipeline is, how mature the data pipeline is, and the level of experience on the data engineering team.
Having more data scientists than data engineers is generally an issue. It typically means that an organization is having their data scientists do data engineering. As I’ve shown, this leads to all sorts of problems.
A common starting point is 2-3 data engineers for every data scientist. For some organizations with more complex data engineering requirements, this can be 4-5 data engineers per data scientist. This includes organizations where data engineering and data science are in different reporting structures. You need more data engineers because more time and effort is needed to create data pipelines than to create the ML/AI portion.
I talk more about how data engineering and data science teams should interact with each other in my book Data Engineering Teams.
Data Engineers doing data science
A far less common case is when a data engineer starts doing data science. There is an upward push as data engineers start to improve their math and statistics skills. This upward push is becoming more common as data science becomes more standardized. It’s leading to a brand new type of engineer.
The need for machine learning engineers
Let’s face it—data scientists come from academic backgrounds. They usually have a Ph.D. or master’s degree. The issue is that they’d rather write a paper on a problem than get something into production. Other times, their programming abilities only extend to creating something in R. Putting something written in R into production is an issue unto itself. They don’t think in terms of creating systems, like an engineer.
The general issue with data scientists is that they’re not engineers who put things into production, create data pipelines, and expose those AI/ML results.
To deal with the disparity between an academic mindset and the need to put something in production, we’re seeing a new type of engineer. Right now, this engineer is mostly seen in the U.S. Their title is machine learning engineer.

Figure 3. Diagram showing where a machine learning engineer fits with a data scientist and data engineer. Illustration by Jesse Anderson and the Big Data Institute.
Machine learning engineers primarily come from data engineering backgrounds. They’re cross-trained enough to become proficient at both data engineering and data science. A less common route is for a data scientist to cross-train on the data engineering side.
My one sentence definition of a machine learning engineer is: a machine learning engineer is someone who sits at the crossroads of data science and data engineering, and has proficiency in both data engineering and data science.
As you looked at Figure 2, you probably wondered what happens to the gap between data science and data engineering. This exactly where the machine learning engineer fits in, as shown in Figure 3. They’re the conduit between the data pipeline a data engineer creates and what the data scientist creates. A machine learning engineer is responsible for taking what a data scientist finds or creates and making it production worthy (it’s worth noting that most of what a data scientist creates isn’t production worthy and is mostly hacked together enough to work).
The machine learning engineer’s job primarily is to create the last mile of the data science pipeline. This might entail several parts. It might be rewriting a data scientist’s code from R/Python to Java/Scala. It might be optimizing the ML/AI code from a software engineering point of view that the data scientist wrote so it runs well (or runs at all). The machine learning engineer has the engineering background to enforce the necessary engineering discipline on a field (data science) that isn’t known for its adherence to good engineering principles.
A model running in production requires care and feeding that software doesn’t. A machine learning model can go stale and start giving out incorrect or distorted results. This could be from the nature of the data changing, new data, or a malicious attack. Either way, the machine learning engineer is on the lookout for changes in their model that would require retraining or tweaking.
Machine learning engineers and data engineers
The transition of data engineer to machine learning engineer is a slow-moving process. To be honest, we’re going to see similar revisions to what a machine learning engineer is to what we’ve seen with the definition of data scientists.
To explain what I mean by slow moving, I will share the experience of those who I’ve seen make the transition from data engineer to machine learning engineer. They’ve spent years doing development work as a software engineer and then data engineer. They’ve always had an interest in statistics or math. Other times, they just got bored with the constraints of being a data engineer. Either way, this transition took years. I’m not seeing people become machine learning engineers after taking a beginning stats class or after taking a beginning machine learning course.
As I much as I razz the data scientists for being academics, data engineers aren’t the right people, either. An engineer loves trues and falses, the black and white, and the ones and zeros of the the world. They don’t like uncertainty. With machine learning, there is a level of uncertainty of the model’s guess (engineers don’t like guessing, either). Unlike most engineers, a machine learning engineer can straddle the certainty of data engineering and the uncertainty of data science.
The increasing value of machine learning engineers
The bar for doing data science is gradually decreasing. The best practices are gradually being fleshed out. The most common algorithms are known. Even better, someone has already coded and optimized these algorithms.
This increasing maturity is making it easier for both data scientists and machine learning engineers to put things in production without having to code them. We’re also seeing data science become a more automatic and automated process. Google’s AutoML is one such trend where it will find the best algorithm for you automatically and give results without requiring the work of a full-fledged data scientist. DataRobot is another technology that is automating the process of finding the right data science algorithm for the data. It will also aid the machine learning engineers in putting that algorithm into production.
These tools aren’t going to replace hardcore data science, but it will allow data scientists to focus on the more difficult parts of data science. It will allow machine learning engineers to become more and more productive. We’ll see a gradually increasing amount of offloading to machine learning engineers and automation of algorithms.
I’m torn on what level of productivity we should expect from machine learning engineers in the future. To grossly oversimplify things, will machine learning engineers be the Wordpress configurators to their web developer counterparts? In this scenario, a machine learning engineer can be productive with very known and standard use cases, and only a data scientist can handle the really custom work. Or will machine learning engineers be the database administrator reborn? Given an in-depth knowledge of the model, they can use a known, cookie-cutter approach to configure a model, get correct results 50-80% of the time, and that’s good enough for what was needed. To get truly accurate results, you would need a data scientist.
The key to the productivity of machine learning engineers and data scientists will be their tools. There’s a lack of maturity now, and that’s why I’m wondering how productive they’ll be in the future.
I expect the bar for doing data science to continue to lower. This will make a machine learning engineer able to accomplish more data science without a massive increase in knowledge. I expect the role of machine learning engineer to become increasingly common in the U.S. and around the world.
What to do?
Now that you’ve seen the differences between data scientists and data engineers, you need to go back through your organization and see where you need to make changes. This is a change I’ve helped other organizations accomplish, and they’ve seen tremendous results. In cases where the data science group seemed stuck and unable to perform, we created data engineering teams, showed the data science and data engineering teams how to work together, and put the right processes in place.
These changes took the data science team from 20-30% productivity to 90%. The teams were able to do more with the same number of people. The data scientists were happier because they weren’t doing data engineering. Management could start delivering value against the promises of big data.
You also met a new position, machine learning engineer. As your data science and data engineering teams mature, you’ll want to check the gaps between the teams. You may need to promote a data engineer on their way to becoming a machine learning engineer or hire a machine learning engineer.
Finally, most problems with big data are people and team issues. They are not technical issues (at least not initially). Technology usually gets blamed because it’s far easier to blame technology than to look inward at the team itself. Until you solve your personnel issues, you won’t hit the really tough technical issues or create the value with big data you set out to create. Take an honest look at your team and your organization to see where you need to change.
*Source: O’Reilly
About Me
I'm a data leader working to advance data-driven cultures by wrangling disparate data sources and empowering end users to uncover key insights that tell a bigger story. LEARN MORE >>
comments powered by Disqus