Coursera- Leveraging Unstructured Data on GCP

COURSE LINK
COURSE CERTIFICATE
Modules & Lab Exercises
Note: These exercises were spun up in temporary cloud instances and thus are no longer available for viewing.
Module 1: Introduction to Cloud Dataproc
What Qualifies as Unstructured Data?
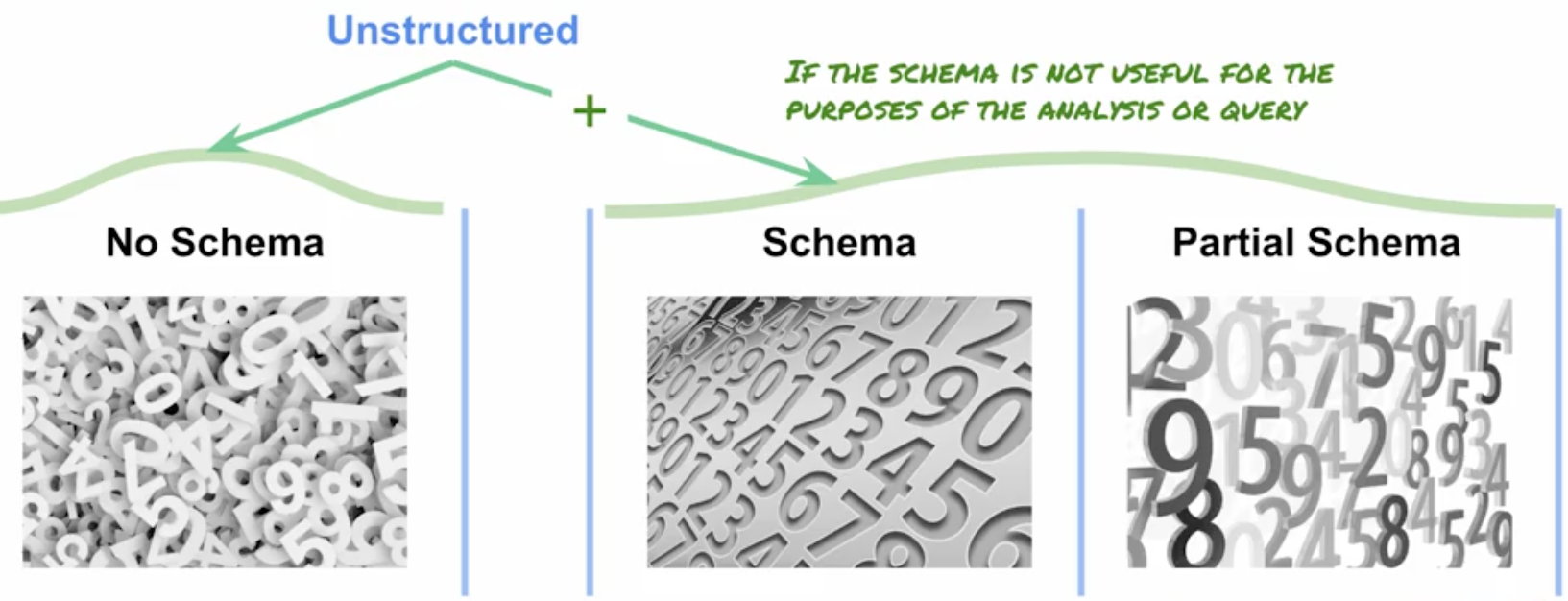
Dataproc Eases Hadoop Management

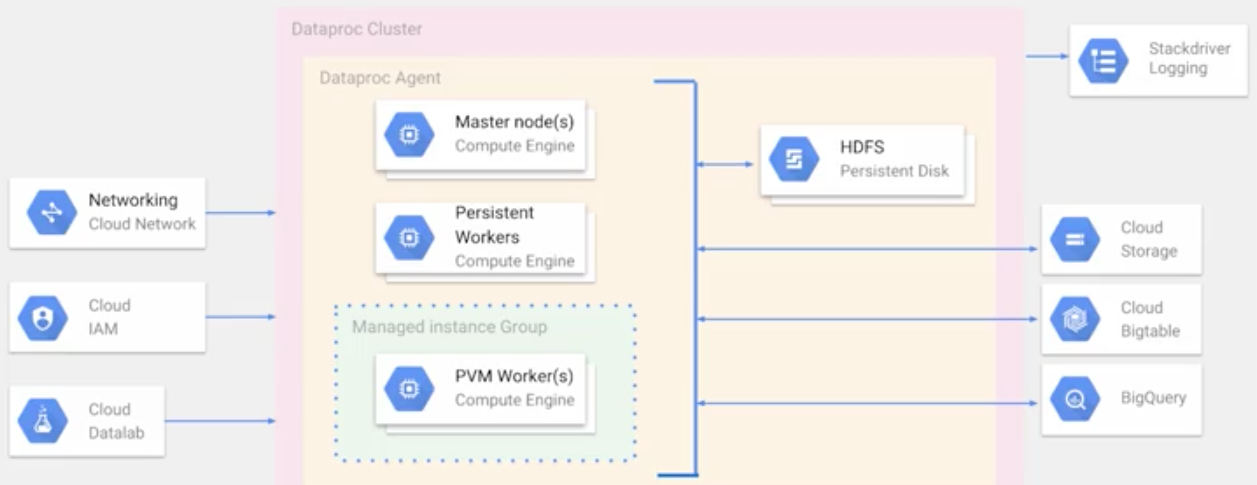
Cloud Dataproc Architecture
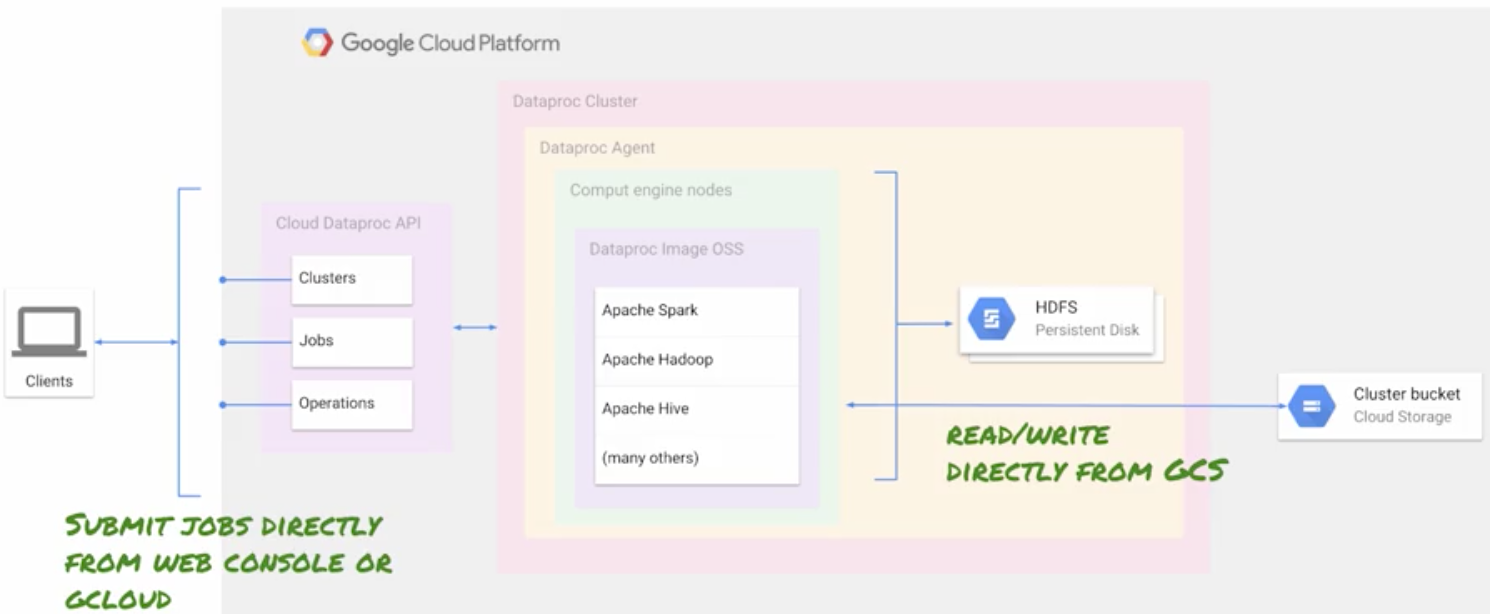
Lab 1: Create a Dataproc Cluster
- Prepare a bucket and a cluster initialization script
- Create a Dataproc Hadoop Cluster customized to use Google Cloud API
- Enable secure access to Dataproc cluster
- Explore Hadoop operations
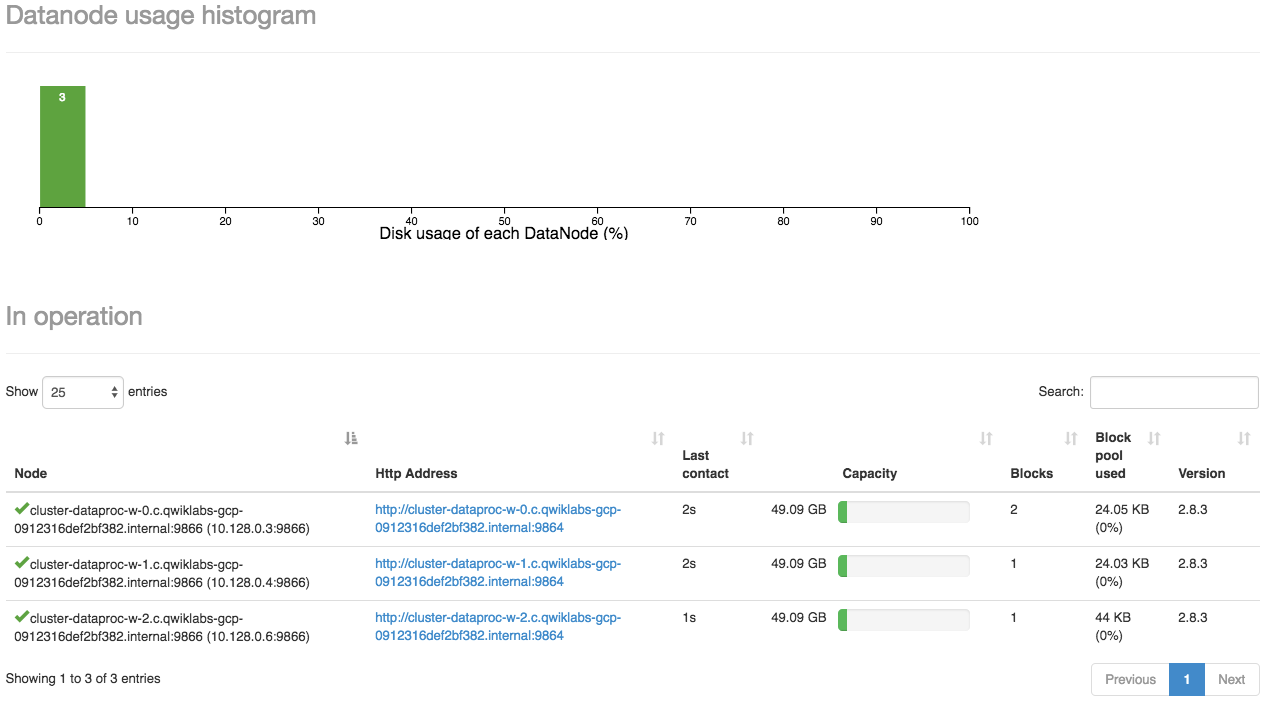
- Use Cloud storage instead of HDFS so you can shut down a Hadoop cluster when it is not actually running a job.
- Hive is designed for batch jobs and not for transactions. It ingests data into a data warehouse format requiring a schema. It does not support real-time queries, row-level updates, or unstructured data. Some queries may run much slower than others due to the underlying transformations Hive has to implement to simulate SQL.
- Pig provides SQL primitives similar to Hive, but in a more flexible scripting language format. Pig can also deal with semi-structured data, such as data having partial schemas, or for which the schema is not yet known. For this reason it is sometimes used for Extract Transform Load (ETL). It generates Java MapReduce jobs. Pig is not designed to deal with unstructured data.
Module 2: Running Dataproc jobs
Open-Source Tools on Dataproc

Data Center Power through GCP
Serverless Platform for Analytics Data Lifecycle Stages
Separation of Storage and Compute Enables Serverless
Separation of Storage and Compute for Spark Programs
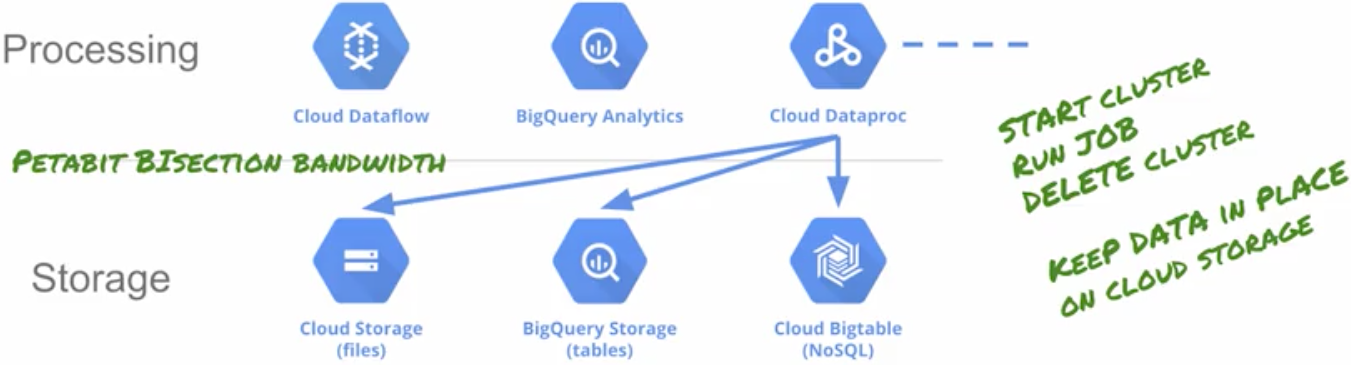
Lab 2: Work with structured and semi-structured data
- Use the Hive CLI and run a Pig job
- Hive is used for structured data, similar to SQL
- Pig is used for semi-structured data, similar to SQL + scripting
Lab 3: Submit Dataproc jobs for unstructured data
- Explore HDFS and Cloud Storage
- Use interactive PySpark to learn about RDDs, Operations, and Lambda functions
File information - road-not-taken.txt

This shows that the file fits into a single HDFS block. Notice from the Block Information pulldown, that the file is only located in Block 0. And that the block is duplicated on both worker node 0 and worker node 1.
- Spark has the ability to run both batch jobs and streaming jobs. It can use in-memory processing for fast results. RDDs or resilient distributed data sets hide the complexity of the location of data within the cluster and also the complexity of replication.
- PySpark is a Read-Evaluate-Print-Loop (REPL) interpreter. Also known as a language shell. The REPL reads a single expression from the user, evaluates it, and prints the result. Then it loops and performs another single expression. The single-step immediate feedback of a REPL makes it useful for exploring and learning a language or system. The limitation is that the REPL holds no state context of its own, unlike more sophisticated shells.
- A Resilient Distributed Dataset (RDD) is an abstraction over data in storage. The RDD is opaque to the location and replication of data it contains. For reliability, RDDs are resilient (fault-tolerant) to data loss due to node failures. An RDD lineage graph is used to recompute damaged or missing partitions. And for efficiency, Spark might choose to process one part in one location or another, based on availability of CPU at that location, or based on network latency or proximity to other resources.
- The benefit of this abstraction is that it enables operations on an RDD to treat the RDD as a single object and ignore the complexity of how data is located, replicated, and migrated inside the RDD. All those details are left to Spark.
- Spark doesn’t perform operations immediately. It uses an approach called “lazy evaluation”.
- There are two classes of operations: transformations and actions. A transformation takes one RDD as input and generates another RDD as output. You can think of a transformation as a request. It explains to Spark what you want done, but doesn’t tell Spark how to do it.
- Actions like “collect”, “count”, or “take” produce a result, such as a number or a list.
- When Spark receives transformations, it stores them in a DAG (Directed Acyclic Graph) but doesn’t perform them at that time. When Spark receives an action it examines the transformations in the DAG and the available resources (number of workers in the cluster), and creates pipelines to efficiently perform the work.
Module 3: Leveraging GCP
Hadoop/Spark Jobs Read From BigQuery Through Temp GCS Storage
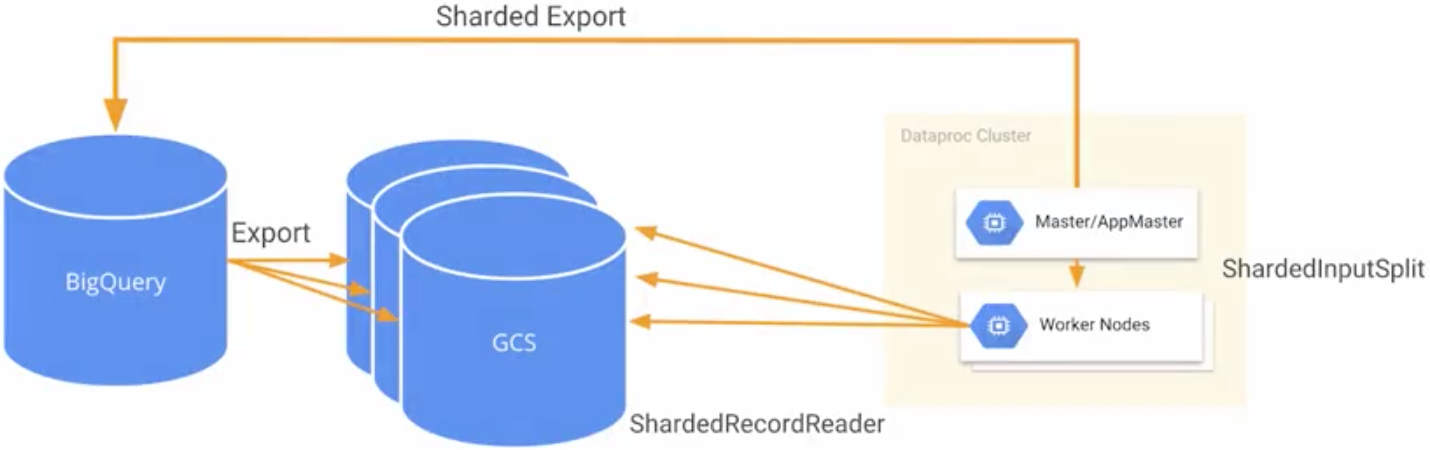
- BigQuery does not natively know how to work with a Hadoop file system. Cloud storage can act as an intermediary between BigQuery and data proc.
BigQuery Integration Using Python Pandas
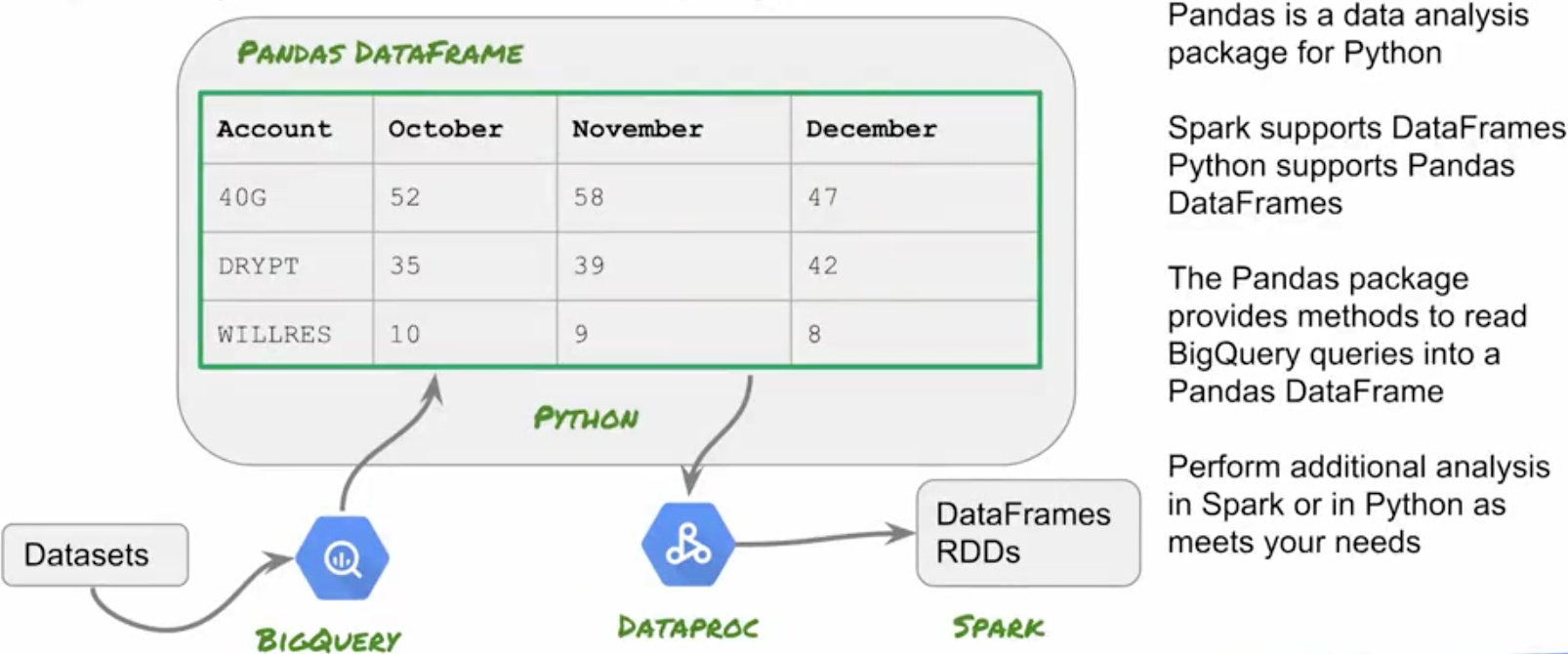
- A Spark DataFrame is a distributed collection of data organized into named columns, conceptually similar to a table in a relational database. A PandasDataFrame can be converted into a Spark DataFrame.
- There are many differences between the Pandas and Spark DataFrames. In general, Pandas’ DataFrames are mutable and easier to work with, and Spark DataFrames are immutable, and can be faster.
- Learn more about Pandas’ DataFrames: pandas.pydata.org
- Learn more about Spark DataFrames: spark.apache.org
Lab 4: Leverage GCP
- Explore Spark using PySpark jobs
- Using Cloud Storage instead of HDFS
- Run a PySpark application from Cloud Storage
- Using Python Pandas to add BigQuery to a Spark application
Why would you want to use Cloud Storage instead of HDFS?
You can shut down the cluster when you are not running jobs. The storage persists even when the cluster is shut down, so you don’t have to pay for the cluster just to maintain data in HDFS. In some cases Cloud Storage provides better performance than HDFS. Cloud Storage does not require the administration overhead of a local file system.
You can make the cluster stateless by keeping all the persistent data off-cluster. And this means (a) the cluster can be shut down when not in use, solving the Hadoop utilization problem, and (b) a cluster can be created and dedicated to a single job, solving the Hadoop configuration and tuning problem.
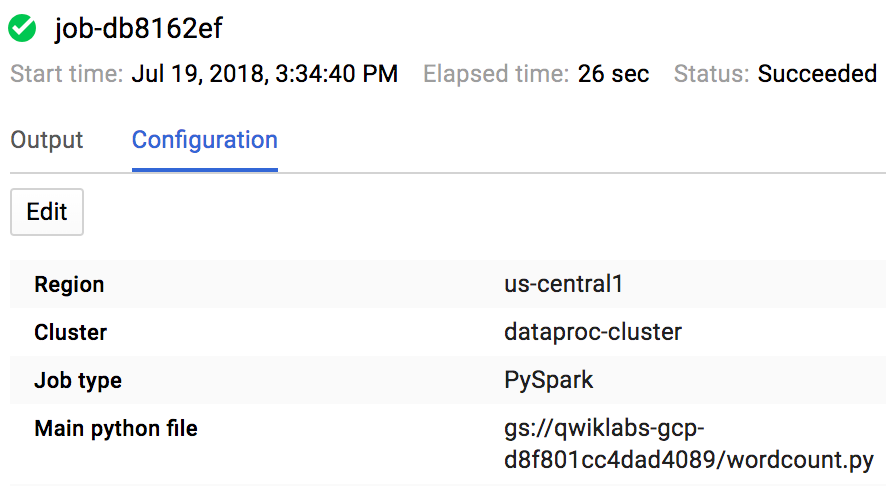
Dataproc OSS on GCP
Lab 5: Cluster automation using CLI commands
- Create a customized Dataproc cluster using Cloud Shell
Module 4: Analyzing Unstructured Data
Pretrained Models
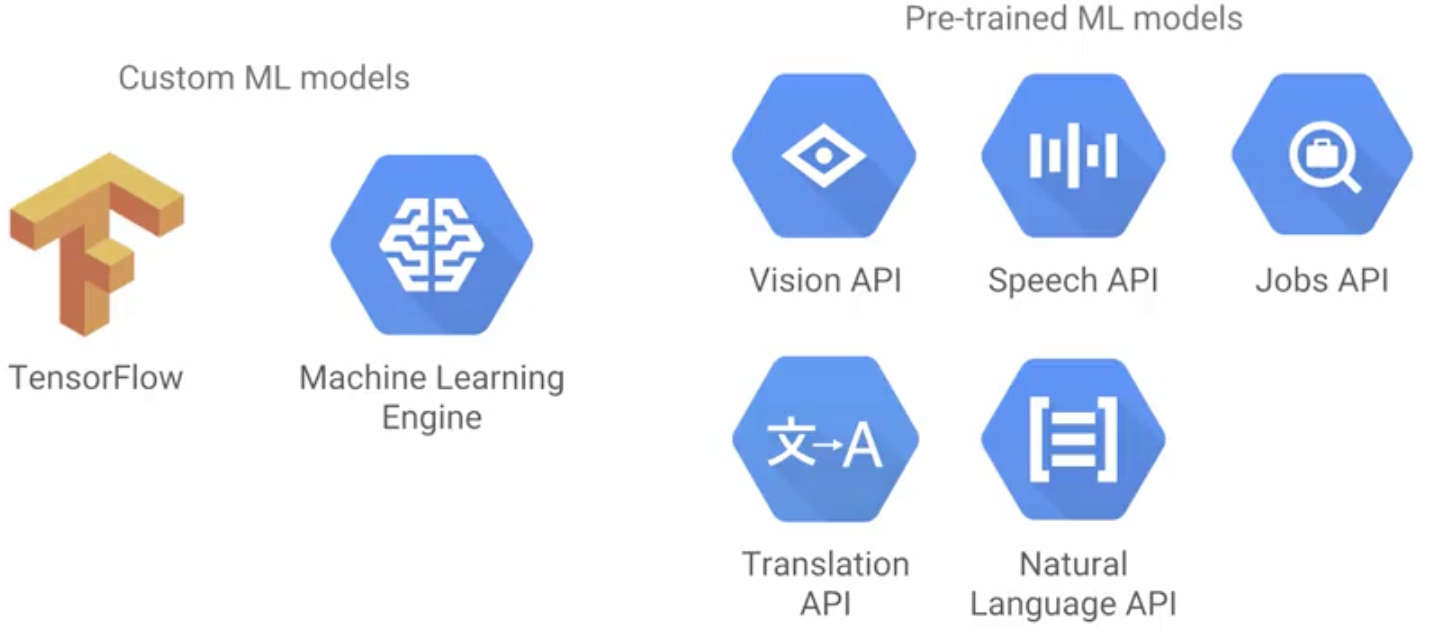
- TensorFlow is a multidimensional matrix solution service. It uses an exhaustion method to generate attempted solutions, and then it uses the error to refine its guess until it converges on a practical solution. It essentially assumes that a solution equation exists and then uses an exhaustion trial method to iteratively search for that solution. The result is called a machine learning model.
Lab 6: Add Machine Learning
- Add Machine Learning (ML) to a Spark application
Resources
- Cluster Scheduled Deletion
- Cloud Dataproc Auto Zone Placement
- Cloud Dataproc Cluster Network Configuration
About Me
I'm a data leader working to advance data-driven cultures by wrangling disparate data sources and empowering end users to uncover key insights that tell a bigger story. LEARN MORE >>
comments powered by Disqus