What is a Productive Data Engineering Team?
written by Jesse Anderson
Merging the gaps between data science and engineering, and what each side can learn from the other.
In my experience working with data engineering teams, I find that most teams don’t realize they have to change their thinking about data and systems to be successful with big data. Data engineering teams need to think about how data is valuable and at what scale the data is coming in. When thinking about scale, I encourage teams to think in terms of 100 billion rows or events, processing 1PB of data, and jobs that take 10 hours to complete.
Imagine processing at 100 billion rows
When you are processing data in real-time or batch, you need to imagine that you’re processing 100 billion rows. This affects how you think about reduces, or the equivalent of reduces, in your technology of choice. If you reduce inefficiently, or when you don’t have to, you’ll experience scaling issues.
Your code should scale to 1PB
When you’re thinking about amounts of data, think in terms of 1 PB. Although you may have substantially less data stored, you’ll want to make sure your processing is planned in such a way that it can handle 1 PB. As you’re writing a program to process 100 GB, you’ll want to make sure that same code can scale to 1 PB. One common manifestation for this problem is to cache data in memory for an algorithm. While that may work at 100 GB, it probably will get an out-of-memory error at 1 PB.
Why you should plan for 10-hour jobs
When you are thinking about long-running processes, I encourage teams to think of processes requiring running for 10 hours to complete. To explain this reasoning, let’s talk about coding defensively. If you have an exception at 9.5 hours into a 10-hour job, for example, you now have two problems: to find and fix the error, and to rerun the 10-hour job.
A job should be coded to check assumptions, whenever possible, and to avoid an exception from exiting a job. A common example of these issues is when a team is dealing with string-based formats, like JSON and XML, and then expecting a certain format; this could be casting a string to a number—if you don’t check that string beforehand with a regular expression, you could find yourself with an exception.
Given the 10-hour job consideration, the team needs to decide what to do about data that doesn’t fit the expected input. Most frameworks won’t handle data errors by themselves—this is something the team has to solve in code. Some common options are to skip the data and move on, log the error and the data, or to die immediately. Each of these decisions is very use-case dependent. If losing data or not processing every single piece of data is the end of the world, you’ll end up having to fix any bad data, manually.
Every engineering decision needs to be made through these lenses. I teach this to every team, even if their data isn’t at these levels. If a data engineering team is truly experiencing big data problems, they will hit these levels eventually.
A data engineering team should be at the “hub of the wheel”
Sometimes I’m teaching at large enterprises and they disagree that there should be a separate data engineering team. In these situations, the enterprise is usually thinking entirely of the technical requirements. Setting a data engineering team at the hub of the wheel puts the team in a completely different light and reveals how the team can become an essential part of the business process.

This hub concept is often foreign or not thought of, and many organizations don’t realize their project will grow in scope. As the other parts of the organization begin to consume the data or use the data pipeline, it becomes clear the data engineering team will need help—usually to fill any skill gaps, often having to do with programming.
Once a data pipeline is first released, it doesn’t stay at its initial usage; it almost always grows. There is pent-up demand for data products that the pipeline starts to facilitate. New data sets and data sources will get added. There will be new processing and consumption of data. In a complete technical free-for-all, you will end up with issues. Often, teams that lack qualified data engineers will completely misuse or misunderstand how the technologies should be used.
How to work with a data science team
Before diving into the relationship between data science and data engineering teams, I want to briefly define the roles. A data scientist is typically someone with a math and probability background, who also knows how to program. Data scientists are often familiar with big data technologies, in order to run algorithms at scale. A data science team is multidisciplinary, just like a data engineering team. The team has the variety of skills needed to prevent any gaps. It’s unusual to have a single person with all of these skills, and you’ll usually need several different people.
The role of data engineer typically requires a strong background in programming and distributed systems, whereas the role of a data scientist typically requires a stronger background in math, analysis, and probabilities; of course, there is some crossover, but the two teams are more complementary than heavily overlapping.
Where data science and data engineering meet
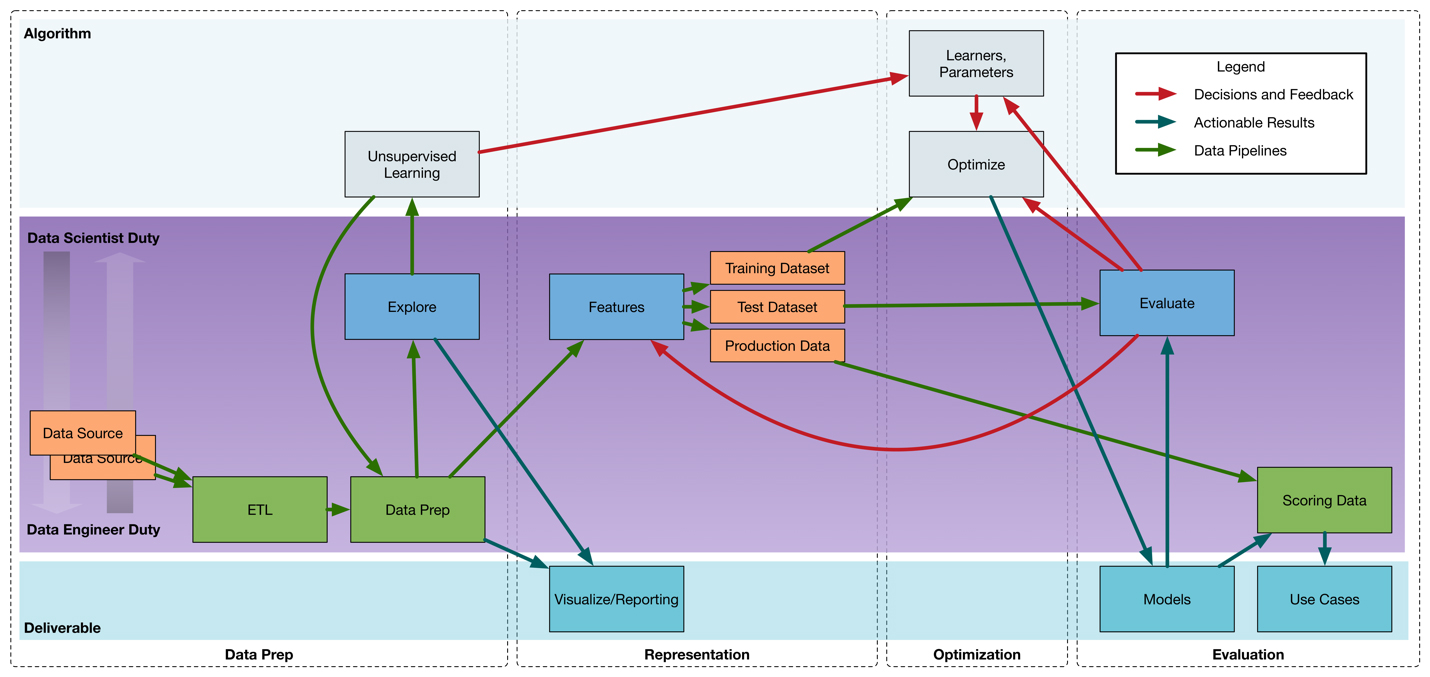
In the image above, I show how tasks are distributed between data science and data engineering teams. I could, and have, talked about this diagram for an hour. The duties are shown as more of a data science or data engineering duty by how close they are to the top or bottom of the center panel. Notice that very few duties are solely a data science or data engineering duty.
There are a few points I want you to take away from this diagram. A data engineering team isn’t just there to write the code—they need to be able to analyze data, too.
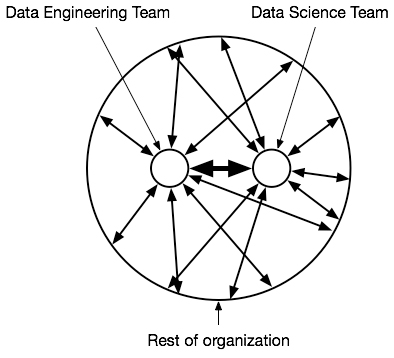
Likewise, data scientists aren’t just there to just make equations and throw them over the fence to the data engineering team—data scientists need to have some level of programming. If the throw-it-over-the-fence scenario becomes the perception or reality, there can be a great deal of animosity between the teams. In Figure 3, I show how there should be a high bandwidth and significant level of interaction between the two teams.
How to work with a data warehousing team
In contrast to the data science team, there is a great deal of overlap with a data warehousing team. Often, the entire reason for creating a data engineering team and moving to big data solutions is to move off of data warehousing products.
Big data technologies can do everything that a data warehousing product can do and much more; however, the skillsets are very different. While a data warehousing team focuses on SQL and doesn’t program, a data engineering team focuses on SQL, programming, and other necessary skills.
The data warehousing team is almost always separate from a data engineering team, yet some companies will rename their data warehousing team as a data engineering team, despite the required skillsets being very different and the levels of complexity between the two teams much greater. Elements from a data warehousing team can sometimes fill in skill gaps in a data engineering team, however—usually domain knowledge and skills in analysis. If you do decide to merge or rename your data warehousing team as a data engineering team, you will need to check for capability gaps. This is a common reason why data warehousing teams have low success rates with big data projects.
*Source: O’Reilly
About Me
I'm a data leader working to advance data-driven cultures by wrangling disparate data sources and empowering end users to uncover key insights that tell a bigger story. LEARN MORE >>
comments powered by Disqus