Becoming a Data Engineer
written by Sergio Sola (with some grammatical edits by me)
Becoming a Data Engineer
I am a software engineer working at HelloFresh. I have been with the company for five years so far. Before HelloFresh and in this company I had different roles.
I started my career as a web developer doing everything, something that nowadays is called ‘full stack developer’ (I have a firm opinion about that position, and it is not good, but that would be another article).
Then I switched for one year to mobile development working for a Dutch company, and finally, I become a backend software engineer for many years. At HelloFresh I had the chance to switch to data engineering a year and a half ago.
In this piece I want to explain my experience and which knowledge you need to learn to become a data engineer. Let me describe some of these topics to you.
Dimensional Modeling (Also Known as Star Model)
This is a data model that can be confusing coming from the entity-relationship model. With dimensional modeling we model the data differently because we have different needs. The basic premise of dimensional modeling is that we have two big components: fact tables and dimensions.
In the fact table as the name states we are storing facts. For example, we sold one item. That order will be a fact, something that happened at some point in time.
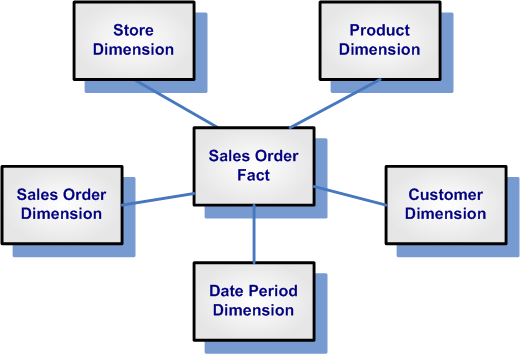
Then, we have the dimensions. A dimension gives some extra information related to that fact. For instance, we can have a product dimension, a customer dimension, date dimension, etc.
The fact table links to the dimension with a surrogate key. This key points to that dimension item at some specific point in time.
To learn more about this I highly recommend the book: The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling.
Knowing Your Infrastructure
Working with data, you will need to build your infrastructure to store and process the data. In this case, you have two different options: use some Hadoop flavor or go to cloud tools like AWS Redshift plus other services.
It’s your decision to choose one or the other, but if you do not want to take care of infrastructure much then I would recommend going for an AWS solution. But if you want to have more control of the whole process, then I would choose some Hadoop flavor.
For Hadoop flavors, I can speak to Cloudera. With this Hadoop distribution, it is pretty easy to start handling a cluster with some nodes and start using the HDFS to store your data in a distributed way.
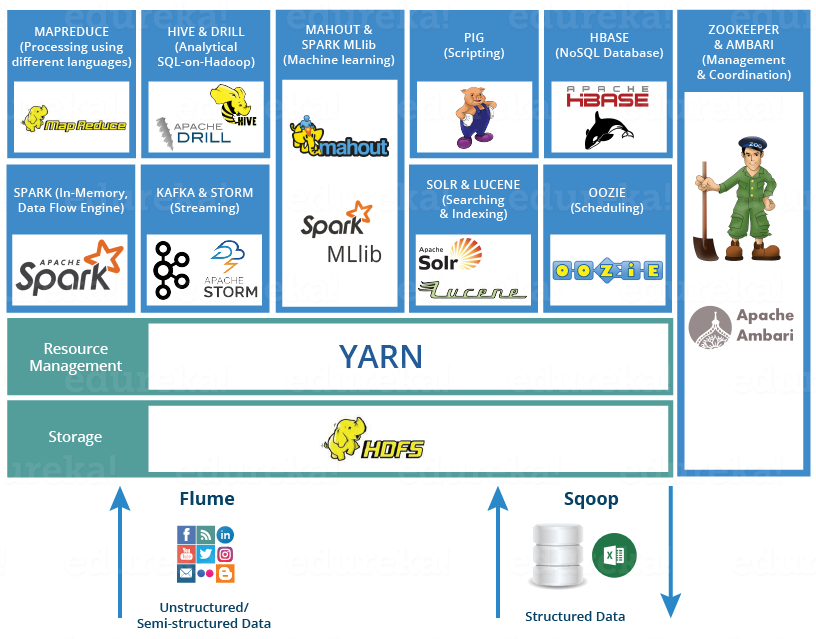
With Cloudera Director + Manager, it is more straightforward to maintain compared with other distributions like MapR.
If you decide to go for the cloud solution, then you will probably use S3 as your data storage and AWS Redshift as the solution to run some processes and query your data.
For your Hadoop distribution to query your data using SQL syntax you can choose between Impala or Drill. I would recommend Impala as an excellent tool to query your data using SQL in combination with the Hive metastore.
As you can see, I just mentioned only a few tools to do some basic stuff. So, switching to data engineering means learning a lot of new technologies.
Analyzing Your Data
When you have the data stored in your distributed system, the next step is to start analyzing the data. As in building some tables to start transforming and aggregating data.
In this case, I will speak about Spark. This is the only tool I have used so far for that purpose. To be more specific, PySpark.
If you choose a Hadoop distribution, you can start doing map/reduce tasks out of the box. But this is already becoming an increasingly outdated approach towards accomplishing your goal.
Nowadays, Spark is a powerful tool to run tasks in a distributed way and it is easy to manipulate and transform your input. Usually, the more natural tasks are batches processes. But if you need some real time analysis you can use Spark Streaming in combination with some message broker system like Kafka.

Some advantage of using Spark is that it supports different languages like Java, Scala, and Python.
With Spark you can push the code to your data nodes and execute the transformations in a distributed way, trying to use the memory of the nodes instead of doing I/O operations on the file system. This is an advantage compared with map/reduce.
Orchestrating your tasks
With the data in your distributed solution, you can use technology to create tasks and orchestrate when to run each task.
In my opinion, one of the biggest tools to achieve this is Airflow. It’s an Apache project with Airbnb as the main supporter. With Airflow, you can create a Directed Acyclic Graph (DAG) to set up the order in which the DAG should execute your tasks. A DAG is a collection of tasks running in a particular order.
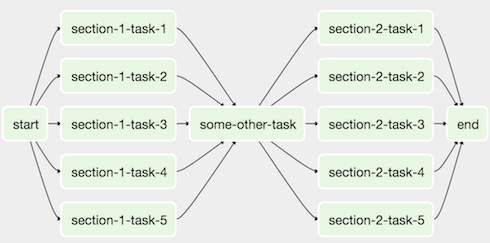
This is also known as ETL (extract, transform, and load) because all the tasks are going to achieve those three necessary steps. Extract the data from an API, transform the data in some way, and at the end load the data into your data solution.
Conclusion
It is possible to switch your career from backend/frontend engineering to data engineering, but you should be prepared to learn a new set of technologies and concepts, potentially very different than the ones you are used to.
So my biggest advice is to be open-minded, humble, and eager to read. Be ready to practice, fail, and start over as you learn.
*Source: Medium.com
About Me
I'm a data leader working to advance data-driven cultures by wrangling disparate data sources and empowering end users to uncover key insights that tell a bigger story. LEARN MORE >>
comments powered by Disqus